Is your business stagnant because you can’t get enough data in the right hands?
DO YOU BELIEVE BIG TECH HAS TOO MUCH POWER OVER THE REST OF US?
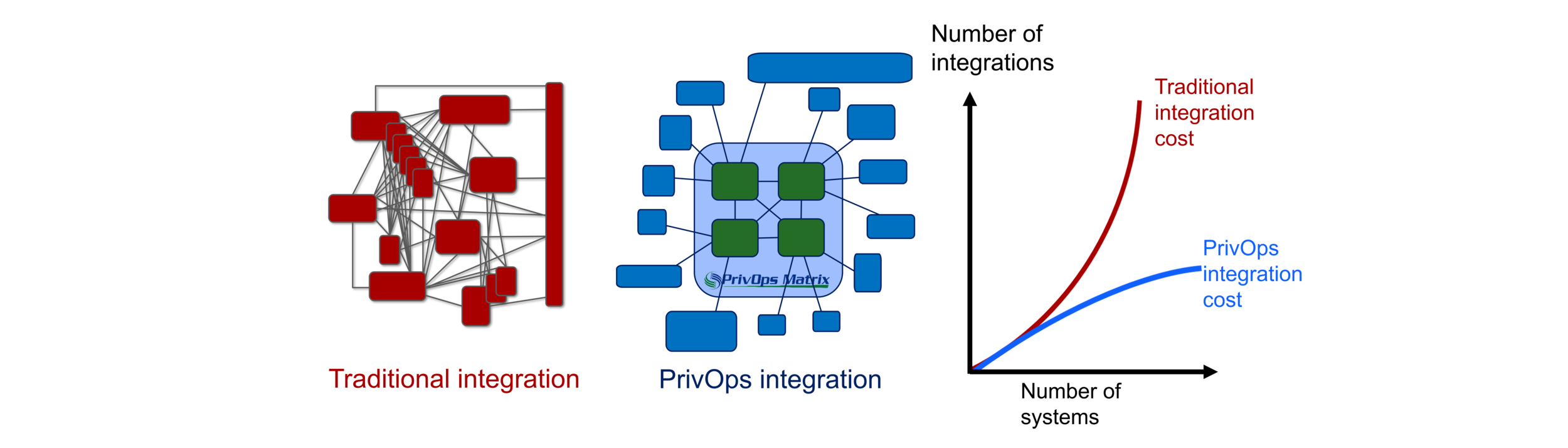
Our open integration fabric levels the playing field by putting you in control of your data in a way that scales
The key to competition in the 21st Century is information supremacy. And the key to information supremacy is data-driven business transformation - weaponizing information both inside and outside the organization. To do that, you first need a platform.
But at what cost? Project failures due to the lack of operational scalability & interoperability, high cost, and poor supportability of traditional tools led big tech to invest heavily in platforms designed to help organizations monetize their data. Unfortunately, because of the need for market power, big tech’s proprietary platforms end up limiting choice and support predatory pricing strategies with low entry costs that explode after it’s too late to switch.
Take advantage of the entire industry’s innovation. What is needed is a platform that flips the script on proprietary architectures that pretend to be open. What is needed is an open ecosystem with a best of breed approach to building and managing thousands of data pipelines.
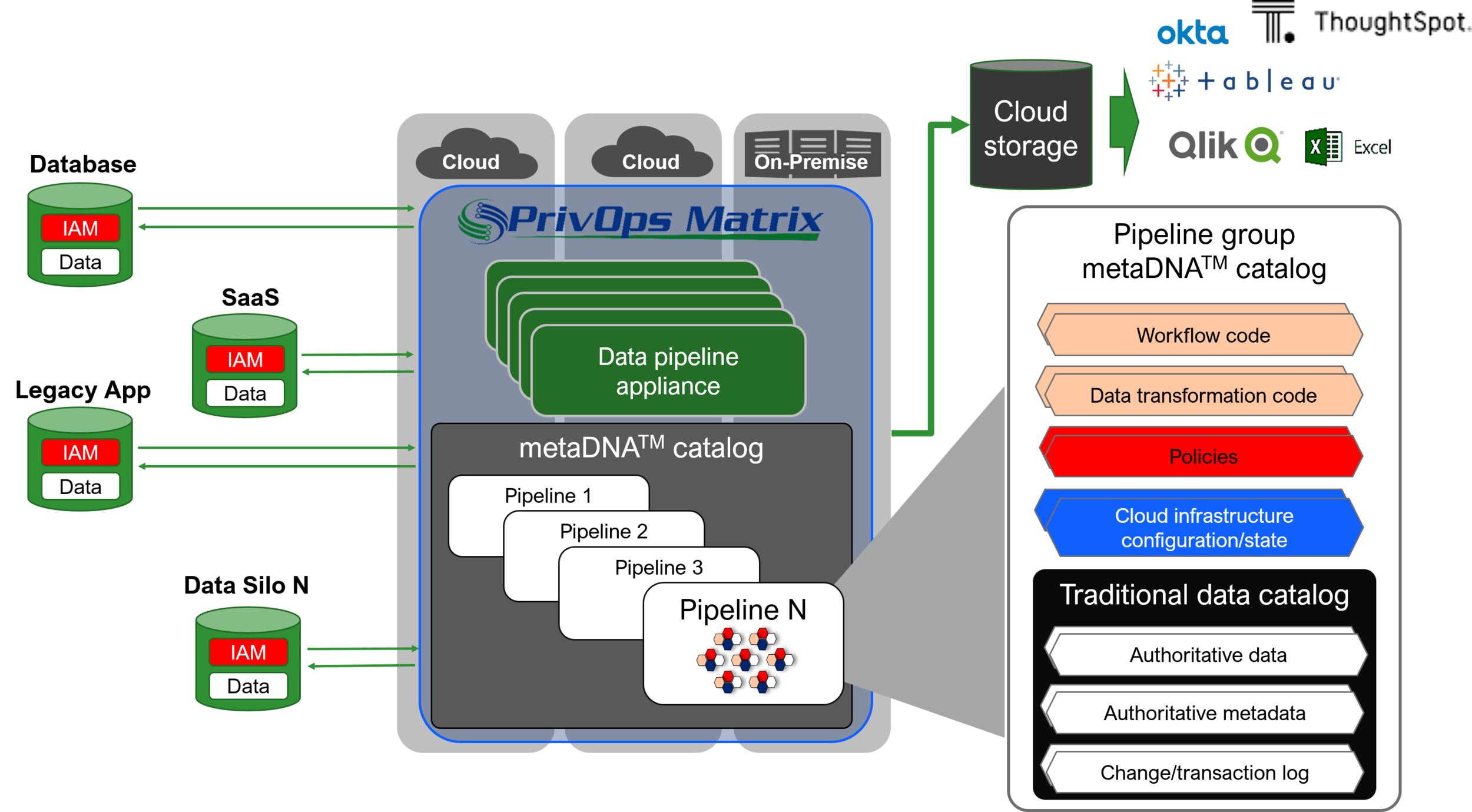
The PrivOps Matrix™
software defined data & applications
Real-time, dynamically re-composable data flows
The award winning PrivOps Matrix™: A data factory for mass producing software defined data pipelines.
The PrivOps Matrix™ creates a modular scaffolding for integrating custom, open-source, and proprietary components that interact with data and applications. The result is a hot-pluggable, best-of-breed enterprise architecture that automates the construction and management of data pipelines.
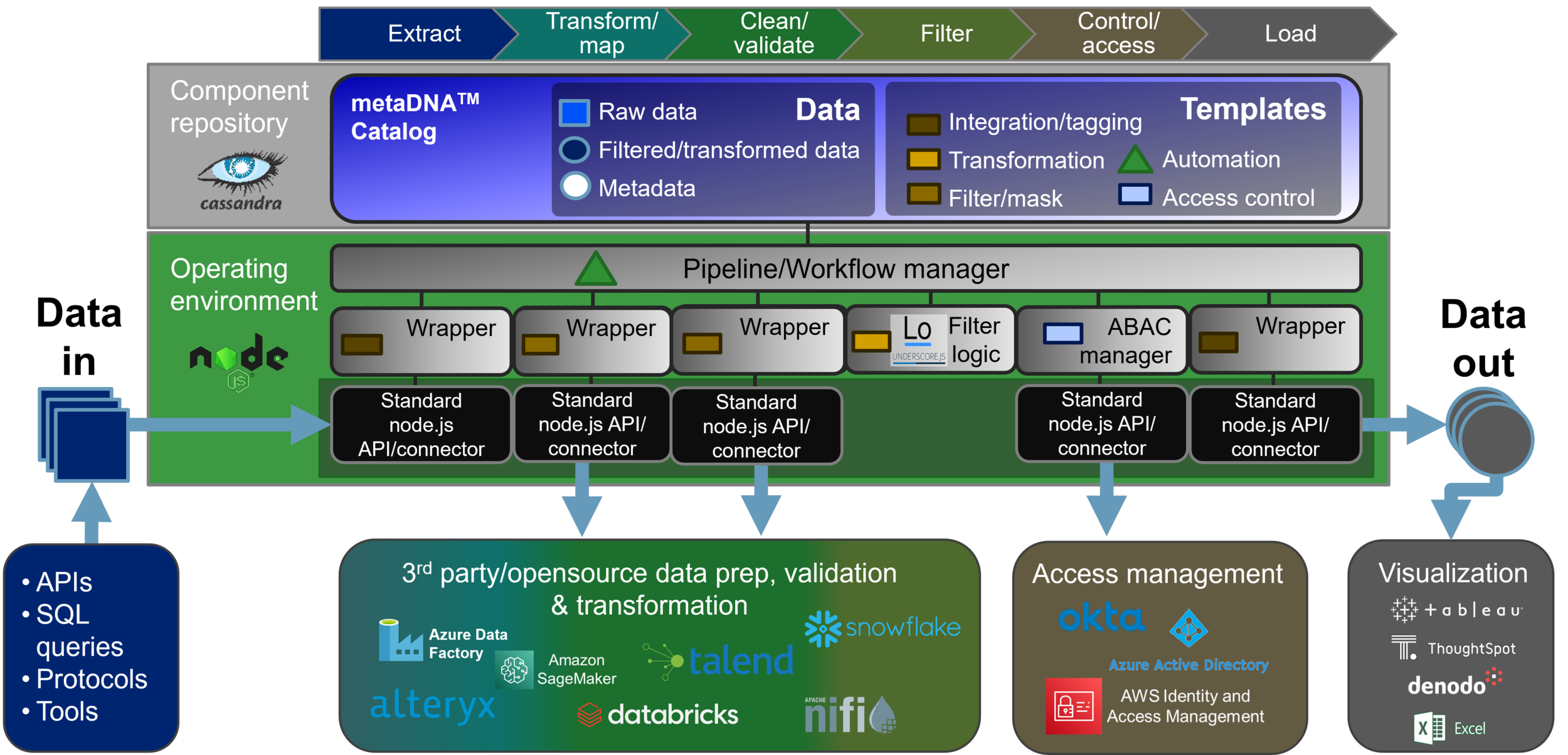
Get control back from proprietary cloud and IT tools vendors by owning your data. You choose what tools to use, switch vendors as needed, accelerate integrations and automations with modular, reusable components, and reduce cost with an integration approach that scales.
Imagine being able to reconfigure data pipelines automatically based on security breaches, changes in cloud pricing, data location, application performance, requestor identity or a host of other situations. Each data pipeline is composed at run-time based on predefined policies. This makes it possible to reuse and share data pipeline components across data pipelines as well as reconfigure data pipelines in real-time. As the data pipeline operates, a decision engine loads different application policies and data dependent on external events and state. This takes data pipeline adaptability to a new level.
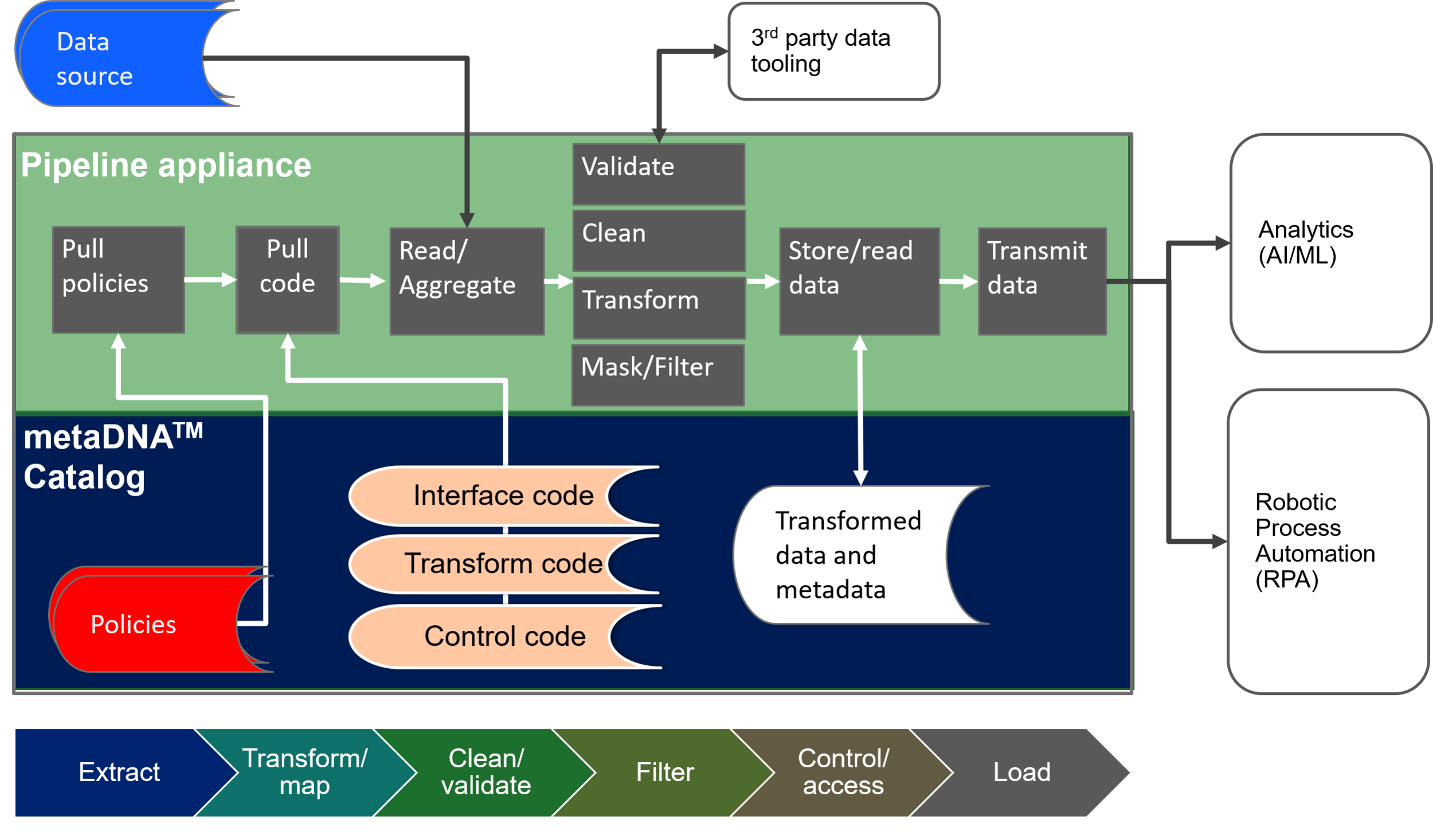
Data On-demand
Any data, anywhere
Create tens, hundreds, or thousands of data pipelines to create a virtual view of your entire organization’s information. Easily share data across organizations. With the PrivOps Matrix™, you extract & process the data only when you need it. As a result, you only touch 5-10% of the data you would have stored in a traditional data lake and reduce infrastructure costs by not needing to process, replicate, or transmit the 90-95% of data you don’t need.