

Using Generative AI with Clean Data to Survive in Shark Infested Waters: GDPR and cybersecurity (Part 1)
When it comes to training data for AI, fix the wiring before you turn on the light.

“Fix the wiring before you turn on the light.”
Introduction
With all the hype around generative AI , it’s not surprising many organizations are incorporating AI into their strategic plans. The problem is, without clean training data, large language models (LLMs) are worthless.
As organizations strive to harness the potential of artificial intelligence (AI), training data is critical. However, in today's data-driven landscape, data privacy and compliance regulations, such as the EU’s General Data Protection Regulation (GDPR), pose massive challenges and are a significant source of data friction as organization seek to monetize their data. There are many other sources of data friction, including organizational knowledge gaps, data/organization silos, vendor lock-in and technical debt, but for the purposes of this article, we will focus on the importance of utilizing a data fabric for integration, security, and data privacy under GDPR, enabling organizations to obtain valuable training data for LLMs while maintaining compliance.
Key Challenges/Opportunities
Pseudonymization and Anonymization
Consent Management
Data Encryption and Access Control
Auditing and Compliance Monitoring
Low Code/Efficiency
Data privacy is a growing concern, and regulations like GDPR have been implemented across the globe to safeguard individuals' personal information. Compliance with these regulations is mandatory for organizations handling and processing personal data. When it comes to training Large Language Models(LLMs), organizations must adhere to the principles of data privacy, consent, and lawful processing. This is a massive challenge for most organizations because they have a mix of both legacy and modern IT systems with sensitive data. Let's explore how a data fabric addresses key challenges related to security and data privacy.
Pseudonymization and Anonymization
Under GDPR, CCPA and other data privacy regulations, organizations are required to protect personal data by pseudonymizing or anonymizing it. A data fabric must enable organizations to apply these techniques during the integration process by automatically replacing identifiable information with pseudonyms or removing personally identifiable information altogether. This ensures that training data used for LLMs is privacy-compliant, reducing the risk of unauthorized access or data breaches. The key is to think about change management - What is the cost of reacting to changes in the regulatory environment? Make sure any data fabric you build or buy has prebuilt data privacy components so new integrations are compliant by design to minimize re-work (technical debt).
Consent Management
Consent is a crucial aspect of data privacy compliance. Organizations must ensure and demonstrate they have obtained appropriate consent from individuals whose data is used for training LLMs. A data fabric must incorporate automated self-service consent management capabilities including automated masking of sensitive data unique to each data requestor. This allows organizations to track and manage consent preferences throughout the data integration process. Training data is then sourced, processed and logged in accordance with the consent given by data subjects, thereby maintaining compliance.
Data Encryption and Access Control
Data security is paramount when handling personal data for LLM training. A data fabric must provide robust encryption mechanisms and automate identity and access management. By implementing encryption protocols, organizations safeguard sensitive training data, preventing unauthorized access, mitigating the risk of data breaches, and giving organizations the fine-grained controls necessary to expose valuable data more broadly to enable citizen data scientists. To be truly secure while providing maximum access to data, a data fabric must follow a zero trust model where access managment is automated. This ensures that data requestors alway have the right permissions to data acces. We’ve also reduced data breach risk by eliminating the chance over-permissioned users or “zombie” users (eg. ex-employees and contractors) are able to access sensitive data.
Auditing and Compliance Monitoring
Data privacy requires organizations to demonstrate compliance and maintain records of data processing activities. A data fabric must enable comprehensive auditing and compliance monitoring, providing organizations with a centralized platform to track data integration processes, access logs, and consent management activities. This facilitates efficient compliance reporting, reducing the administrative burden on organizations.
Low-Code Integration for Efficiency & Scalability
As is the case with most technology projects, data integrations are traditionally project based. Because IT project requirements don’t usually take into account the effects on future work, the result is a large number of point-to-point integrations that fail to re-use prior work; each new integration project gets more expensive, more complicated, and more likely to fail. The current IT industry approach hasn’t helped either. While most vendors pay lip service to interoperability, the reality is quite different. Technology vendors create platform stickiness (lock-in) so they can:
Sell additional products and raise prices by controlling or limiting how their platforms work with other technologies
Make it more difficult to switch vendors
Force you to buy features you don’t want or need
Simply put, it is in the financial interest of cloud data platforms and integrators to create proprietary data structures and interfaces that make it difficult to be replaced when contracts end. What is needed is flexibility and efficiency, not lock-in. Organizations need a low-code, hot-pluggable data fabric for interchanging custom, open-source, and proprietary components. This is critical because organizations need to be able to swap out AI vendors and integrate new sources of training data as newer platforms emerge.
The alternatives are:
Build a data fabric yourself
Use a IT platform vendor with a walled garden approach to data integration that limits flexibility and makes you pay for things you don’t need
Use best-of-breed data fabric solution that prioritizes interoperability and use of open source to create a force multiplier (like the PrivOps Matrix)
By utilizing interoperable, low-code data integration, organizations can comply with data privacy requirements in a way that scales, ensuring that only authorized and compliant data sources are used for training LLMs and other forms of Machine Learning (ML).
Conclusion
To get the most out of their AI strategy, organizations must strike a delicate balance between obtaining valuable LLM and other ML training data, operational efficiency, and maintaining compliance with GDPR and other data privacy regulations. Embracing a data fabric for integration, security, and data privacy is essential for achieving this balance. By leveraging the capabilities of a data fabric like the PrivOps Matrix, organizations can streamline data integration, ensure GDPR compliance, protect personal data, and enhance training data quality for LLMs. With these measures in place, organizations can unlock the full potential of LLMs while upholding the principles of privacy and data protection in today's data-driven world.
Tyler Johnson
Cofounder, CTO PrivOps

Agile Strategies for Startups: Harnessing the Power of Agility
We should consider the context in which Agile will be implemented when strategizing for startups. To better understand the benefits and challenges of using Agile in startups, let's look at various examples of good and poor implementations.
We should consider the context in which Agile will be implemented when strategizing for startups. The objective of incorporating Agile should be to improve efficiency and productivity across the engineering department, regardless of size. We want to decrease development overhead (e.g., excessive meetings, complex workflows, redundant tasks, etc.). To better understand the benefits and challenges of using Agile in startups, let's look at various examples of good and poor implementations.
No Implementation
Without an Agile strategy, a company may struggle with a lack of flexibility, limited communication and collaboration between teams, difficulty adapting to changing customer needs or market conditions, and difficulty estimating project timelines. An Agile approach provides structure that can prevent complexity and inefficiency. This can lead to missed deadlines, decreased customer satisfaction levels, lower quality products or services delivered to customers, higher costs due to rework, or delays in delivery times.
At the start of my career as a developer, I worked with a small engineering team at Far Corner Technology in Columbia, Maryland. Without any guidelines or structure to our work, we had a startup mentality that led to production and deployment issues. We tested new features in production instead of using separate testing environments and lacked structure for workloads or meetings discussing upcoming projects and initiatives. Tracking progress was also challenging since we relied on manual change logs.
Solid Implementation
A company that has a solid implementation of an Agile strategy is one that understands the value of collaboration and adaptability. Such a company will have established processes in place to ensure teams are working together efficiently, such as sprint planning meetings and retrospectives. They also understand the importance of having clear communication between team members so everyone is on the same page with tasks and goals.
At my second career job at mHelpDesk in Fairfax, Virginia, I gained hands-on experience with Agile and its practical application. As a mid-level developer on a team of 8-10 developers that continued to grow, I was introduced to proper Pull Requests and work tracking through a task management system (Jira). Through the Agile process which included Ticket Grooming, Sprint Planning, and Retrospectives, I could see the impact of my work on the customer - it was an incredibly fulfilling experience.
Additionally, I had the opportunity to take on a full stack development role for building out a separate scheduling module project which we successfully delivered within a few months. With the Scrum meetings, we wouldn’t have been able to pull that off. Through this experience, I gained an appreciation for how much more effective Scrum is than Kanban in an Agile work environment.
Corporate Implementation
A corporate company that has an overkill implementation of an Agile strategy may cause teams to struggle with efficiency due to too many processes and layers in place. These companies often require multiple meetings and reports just for the approval of a task or project before any development can begin, leading to long delays between the start of a project and its completion as bureaucracy takes precedence over actual progress.
Furthermore, these organizations tend not be as open with their communication compared to other companies using more streamlined approaches; this makes it difficult for team members to understand what's expected from them during each phase which can lead to misunderstandings or missed deadlines down the line.
At my third career job with Angi in Indianapolis, Indiana, I moved into a full-blown manager position. In addition to acting as the Scrum Master for our projects, I was now managing my fellow developers. Here, I saw first hand the downside of running Agile in a large company. Despite our team delivering work quickly and having well defined processes that were documented and directed, we still didn't receive much recognition within the company due to so many other initiatives being undertaken at once.
There was a lot of bureaucracy to get through in order to have work accomplished and released. The processes were so precisely defined and structured that it required navigating multiple layers just to have one's voice heard. Our team ran efficiently within these processes, but we felt like a small cog in a large machine.
Startup Implementation
A startup company that utilizes a streamlined Agile strategy without bureaucracy but with structure understands the value of collaboration and adaptability. They have established processes to ensure teams work together efficiently, such as sprint planning meetings and retrospectives. Clear communication between team members ensures everyone is on the same page with tasks and goals.
This approach provides quicker delivery times due to less time spent navigating complex bureaucratic systems. It also allows for more flexibility when changes or unexpected roadblocks arise during development, since there's not as much red tape to cut through in order to make adjustments along the way. Additionally, experimentation leads to innovation within organizations as well as improved customer satisfaction due to more frequent releases with fewer bugs or other problems associated with them.
By streamlining their process while still maintaining structure, startups can get projects completed effectively without sacrificing quality. All stakeholders know what's expected from them throughout each phase which helps build trust amongst team members and keeps everyone focused on meeting deadlines rather than dealing with unnecessary paperwork or waiting for approvals from higher-ups who may be unfamiliar with how software projects should actually be run.
Conclusion
I believe there is a balance between process and relationships in Agile. Structure is important for the development process. But without a connection to the bigger picture, developers may feel like they are just working without seeing results.
When working with a team of 4 or more developers, the Scrum method can be effective as it provides structure for the development process, enables tracking of work, and allows for team discussions on the work's progress. However, the approach should not become bureaucratic, where developers are disconnected from the actual usage of their work or where changing processes takes too long.
In a startup environment, the Agile approach may need to be modified to allow for a more constant stream of work. Rather than having Sprint Planning meetings, have longer-term roadmap discussions and work on larger batches of features. Instead of scheduled retrospectives, have daily discussions on what is going well or what needs improvement.
Tracking work using a task management system and having a proper testing strategy are crucial. Testing should be done in a separate environment before going live and using a Pull Request method to review work can provide a clear history.
In conclusion, structure in the development process is important but should not take priority over the relationship with the development team. Maintaining a balance between relationships and process is crucial in the development world.

Tyler Candee
Vice-President of Engineering, PrivOps

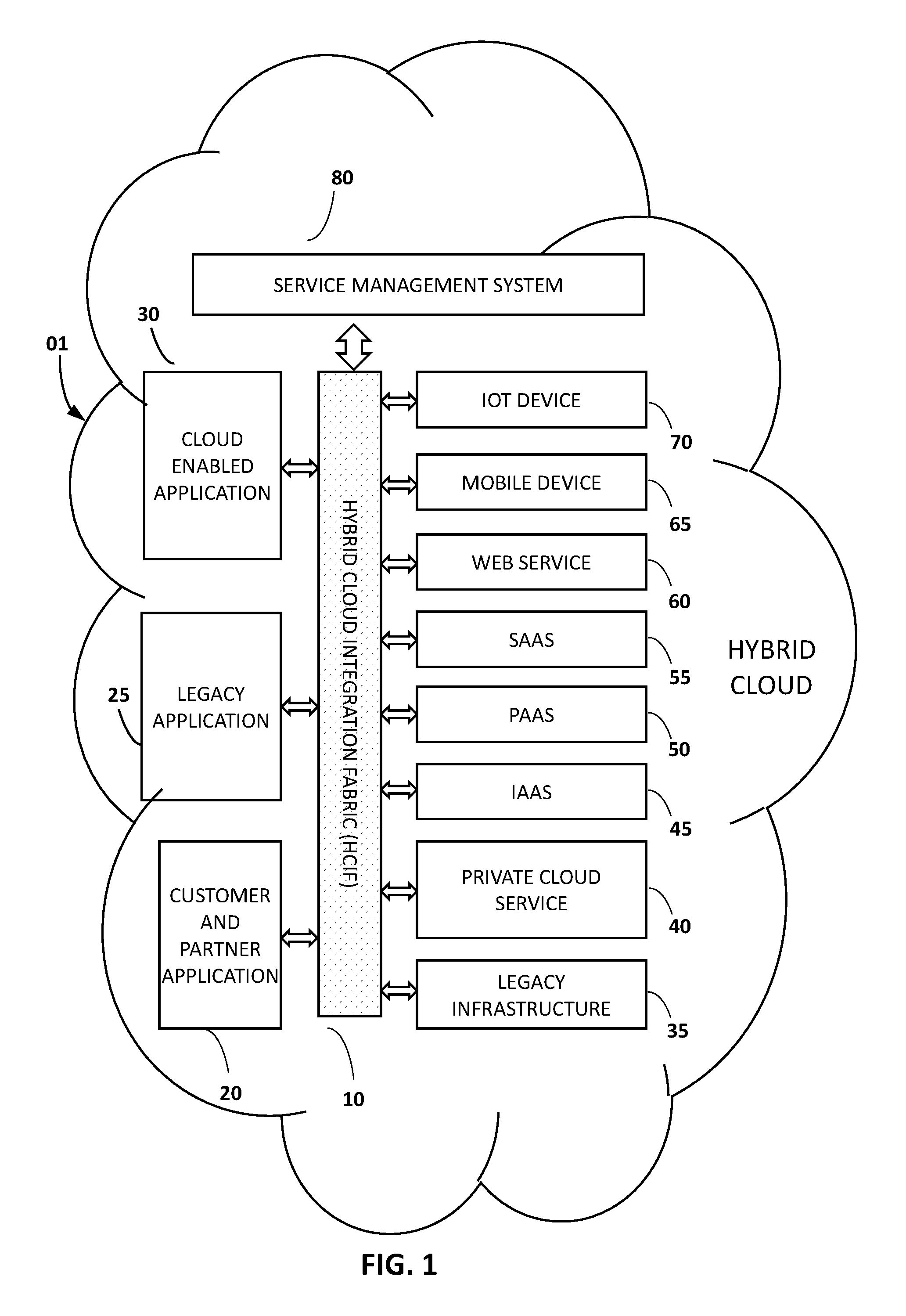
How metaDNA™ is different than microservices, containers and APIs
There is quite a bit of buzz and confusion around microservices, containers, API’s, service meshes, and other emerging technologies related to “cloud-native” application development and data integration; unfortunately, PrivOps has been caught up in the confusion. I often get questions about our (now patented) technology, specifically metaDNA™, the core of our technology, where folks try to categorize us incorrectly.
'To be clear, metaDNA™ is not an API manager (e.g. Mulesoft), a container orchestrator (e.g. openShift), a service mesh (e.g. Istio), a integration platform (e.g IBM IIB), a master data manager (e.g. Informatica), it is an entirely new category. Let me explain. (And yes, I understand that the vendors mentioned above have products that span multiple categories)

To understand metaDNA™, first we need some context. For example, the concept of a microservice is an abstraction that is a manifestation of the interplay between modularity and atomicity (i.e. irreduciblity) at the software architectural layer. There are many other other abstractions at and between other layers of the technology stack, including the interface (e.g. APIs, UIs), server (e.g virtual machine, container) the network (e.g. packets, protocols), the structural (e.g. object-oriented, functional constructs), the language (e.g. high level software instructions that abstract assembly language instructions that abstract hardware operations), and so forth.
Two important questions are:
Is there currently a modularity gap that sits between microservices (software architecture), functional programming and data structures?
Would it matter if an abstraction filled that gap?

Is there a modularity gap that sits between microservices, functional programming and data structures? The answer is yes, which is what my metaDNA™ ontology (and the metaDNA™ catalog that implements the metaDNA™ ontology) attempts to remedy. For those unfamiliar with the term ontology, it is simply a structured way of describing (or building in this case) a class of object structures and the relationships between those objects. (More on ontologies here.) Because of its ontology, the metaDNA™ catalog serves as an abstraction layer that sits between (and unifies) microservices, functional programming and data structures and constitutes an entirely new paradigm for building digital technology. metaDNA™ builds on other abstractions like microservices and containers, but doesn’t necessarily replace them. Like biological DNA, metaDNA™ objects have 4 atomic types, with uniform structures. In the same way biological DNA composes lifeforms, objects from the metaDNA™ catalog compose software components (microservices) AND data structures from EVERY type of structured data. This approach creates the opportunity for several advantages for hybrid cloud applications, including self-referential data and applications, data defined software applications that reconfigure based on context, policy driven application behavior changes, and several others.
Does it matter if an abstraction layer fills the gap between microservices (software architecture), functional programming and data structures? Absolutely, because without it, microservices based software architecture complexity growth is still exponential, even with the use of APIs, containers and service meshes. For example, the cost point to point integration among legacy and modern systems grows exponentially at the rate of ½KN(N-1) where K is the cost of each integration and N is the number of connections. Adding tools adds a similar exponential cost growth. While the modularity afforded by various solutions at the API, microservice and other layers flattens the cost curve, without addressing the modularity gap between the application and data layer the curve is still exponential and still runs into scalability problems, especially for situations like Digital Transformation that requires integration of large numbers of legacy systems and edge computing (even with 5G).
- Tyler

PrivOps awarded contract with US Air Force
Alpharetta, GA. — PrivOps, the leading open data fabric provider, is proud to announce that the US Air Force Small Business Innovation Research (SBIR-STTR) team has selected PrivOps in partnership with JJR Solutions, LLC in a competitive bid process, and PrivOps is officially under contract with the US Air Force. PrivOps has been tasked with creating a plan to leverage their patented data integration, automation, and application development technology to solve some of the US Air Force’s most pressing needs. (More about their recently granted patent here.) PrivOps has already obtained signed commitments from multiple organizations within the US Air Force to support PrivOps’ efforts operationalizing their platform for the Air Force’s needs. Here are some of the needs the Air Force has identified that PrivOps and JJR Solutions are working to address:
Provide automated, policy-driven control of registering transactions on blockchain technologies (e.g., Hyperledger) to secure software chain of custody and detect malicious code manipulation
Provide an event-driven service mesh that makes it possible to detect threats and other operational events and respond in near real-time (self-healing applications)
Implement a distributed Enterprise Information Model (EIM) to support deployment of a data aggregation and transformation system in the cloud
Enable a zero-trust model and Attribute-Based Access Control (ABAC) for automating data governance between modern and legacy systems to support new data analytics, multi-domain operations (MDO), and multi-domain command and control (MDC2) capabilities
Create cross-domain data pipelines with microservices that incorporate best-of-breed, interchangeable commercial off the shelf (COTS) and open source artificial intelligence (AI) and machine learning (ML) software solutions, making it possible to take advantage of new technologies as they become available
“We are delighted to be working with the US Air Force, and are extremely impressed by their commitment to innovation. We are also excited to be partnered with JJR Solutions, LLC in this effort and look forward to leveraging their world class expertise around data, integration, and governance. We look forward to helping the Us Air Force make our warfighters more effective, safe and secure as they protect our nation” - Kit Johnson, CEO, PrivOps
About the USAF SBIR-STTR Program
AFRL and AFWERX have partnered to streamline the Small Business Innovation Research process in an attempt to speed up the experience, broaden the pool of potential applicants and decrease bureaucratic overhead. Beginning in SBIR 18.2, and now in 19.3, the Air Force has begun offering 'Special' SBIR topics that are faster, leaner and open to a broader range of innovations.
Learn more about the US Air Force’s SBIR-STTR program at https://www.afsbirsttr.af.mil/
About PrivOps
The PrivOps Matrix is a next-generation data and applications integration platform designed to optimize the process of incorporating new technologies into data flows and integrating applications and data at scale. Proprietary point-to-point and service bus integration architectures requiring specialized talent create processes that don’t scale and are difficult to support; the PrivOps Matrix multi-cloud integration platform minimizes rework and maximizes re-use with an open, scalable, and agile hot-pluggable architecture that connects best-of-breed vendor and open source solutions to both modern and legacy applications and databases in a way that is much easier to support and maintain. As a result, US Air Force information technology will adapt faster to an evolving battlespace by being able to apply agile processes to integration while combining best-of-breed tools and emerging technologies with legacy systems.

PrivOps receives US patent 10,491,477 for the PrivOps Matrix
We are excited to announce that as of 12/18/2019, the PrivOps Matrix is officially patented. US patent 10,491,477, Hybrid cloud integration fabric and ontology for integration of data, applications, and information technology infrastructure” is confirmation of PrivOps; technical leadership and innovation in helping organizations deal with data sprawl by making is easier to protect and monetize data wherever it lives.

By integrating, governing and automating data flows between complex systems, the PrivOps Matrix serves as the foundation for building hot pluggable information supply chains that monetize data. We control, at scale and in real time, where sensitive data lives, how it’s processed & stored, and when, who or what has access.
The key innovation in the Matrix data fabric is the patented metaDNA catalog. Just as biological life is built from structures defined by standard sets of genes composed with reconfigurable DNA molecules, “digital molecules” stored in the metaDNA catalog are combined to create “digital genes”. These recipes will make it possible to build self-assembling microservices, applications, integrations, and information supply chains that can be reconfigured in real-time as the environment changes. The result is IT technology that will be more scalable, resilient and .adaptable than anything that exists today.
This is a momentous occasion for PrivOps. Special thanks goes out to Daniel Sineway, our patent attorney at Morris, Manning & Martin, LLP and our advisors Scott Ryan (ATDC), Walt Carter (Homestar Financial), Gary Durst (USAF) and many others who have supported us so far.

The PrivOps Matrix is Selected as a Finalist for 2019 Air Force AFWERX Multi-Domain Operations Challenge
We are honored to announce that PrivOps has been selected as a finalist in the AFWERX Multi-Domain Operations (MDO) Challenge!
We are honored to announce that PrivOps has been selected as a finalist in the AFWERX Multi-Domain Operations (MDO) Challenge! We will be pitching to the Air Force at their big conference hashtag#AFWERXfusion19 in Las Vegas July 23-24. In addition, we are delighted to announce that we are partnering with JJR Solutions, LLC as they bring purpose-driven capabilities to improve the health, well-being, and security of our communities and nation. We share the same desire for our country to be strong and knowing MDO is a top area of focus for the Air Force and Department of Defense makes us highly motivated. This competition gives us the opportunity to help our country automate data governance through trusted open-source software and our data fabric. Our solution supports real-time decision-making and allows the flow of data to be stopped instantly if a threat is detected. Very exciting! AFWERX MDO
Challenge info: https://lnkd.in/ghQeGAv
Conference info: https://lnkd.in/erkv269


GDPR is Eating the World - Part 2
Think about it – if your organization gets much better at handing data, what else can it do?

You’ve heard it all before.
- Software is eating the world
- Data is the new oil
- Monetize your digital assets
You believe how well a company uses and manages data is the key to 21st century competitiveness.
You might have even sent some colleagues a link to Andreesen’s Software is eating the world article. No response. Many of us have fallen into the same trap.
"Better, faster, cheaper doesn’t sell – With a world suffering from information overload, no one’s buying."
Bottom line: With a technical value proposition, you must show, not tell.
Imagine if Henry Ford had sold his first car based on a pitch about his assembly line. Wouldn’t have gone over so well. Instead, he used assembly line’s technical value proposition (remember there were over 100 car manufacturers at the time) to create a car at a new price point. Instead of better, faster cheaper, the value proposition was –
“Now you can afford the same transportation as the rich”
What does this have to do with GDPR?

With 99 recitals, GDPR does many things, but a core underlying concept is Privacy by Design. What this means is that organizations with EU resident data need to design in privacy from the ground up. In other words, companies must get (a lot) better at controlling data.
Unfortunately, this is just another version of the better, faster cheaper story: It doesn’t sell either to customers, or to other executives in the company.
Think about it – if your organization gets much better at handing data, what else can it do?
If you’re a b2b marketing or financial payments company, you could extend your offerings to include data governance for your customer’s customer data.
“Now you can afford the same data governance as the rich companies”
If you’re a commercial banker, you could avoid regulatory fines while finding the experiences millennial crave and create richer, experience-based customer engagement with your payment solutions.
“Now you can afford to be treated with the experiences you deserve”

The point is, even though ignoring the operational risks I mentioned in Part 1 of this article could land your organization on page 1, that pitch doesn’t win you friends (or customers) either inside or outside your organization (except, perhaps your CFO).
A better approach for legal, compliance & operational professionals
is to attempt to partner with the business to create new customer engagement, with richer experiences, more personalization and attack or create new markets with new business models. Like going to the gym, universal data governance is building new muscles and endurance. But sell the hike to Machu Pichu or the new girlfriend, not the long trips to the YMCA.
GDPR presents a trigger point: Don’t fall into the better, faster, cheaper trap.
There’s a sad reality though – most people who buy gym memberships never set foot in the gym a second time. The same is true with data governance/GDPR compliance. Given the short term thinking prevalent in so many organizations, many executives in these organizations are not interested in the heavy lifting required to put data governance in place as a catalyst for richer customer engagement and access to new markets.
In that case, the right time to push for GDPR compliance in operations will be after the front-page article comes out, or after the organization is disrupted by digital natives like Amazon or Apple. At that point it will be too late of course…

This is the second part of a 2 part article on GDPR. You can find the 1st part here.
Learn more about how to how to solve for GDPR through automation at www.privops.com

GDPR: the tip of the iceberg - Part 1
You've updated your cookie polices, your privacy notices, contracts & agreements. Brand new process documents are in place. It was quite the fire drill, but you're ready for GDPR. Time for some well deserved rest.
Then you get the call
Job well done, it's time to celebrate!

You've updated your cookie polices, your privacy notices, contracts & agreements. Brand new process documents are in place. It was quite the fire drill, but you're ready for GDPR. Time for some well deserved rest.
Then you get the call
A complaint was filed by someone who visited your website anonymously claiming they asked for all their data to be deleted under GDPR's Right to be Forgotten requirement and your company never provided a confirmation receipt. Now Ireland's ICO (information commissioner's office) has launched an investigation. "How is that possible, we don't even have an office in Ireland, and the user was anonymous for goodness sake!", your CEO remarks. After the investigation, it turns out that, even though you have documented processes and trained your employees, nearly 25% of the 200 or so monthly right to be forgotten, data portability, data access, and profiling opt-out requests were dropped. To make matters worse, a low level marketing manager provided thousand of customer records containing sensitive data to an marketing analytics startup that was promptly hacked. You didn't know about it, so you're also in violation of GDPR's 72 hour breach notification requirement.
The good news, the regulator tells you, is that you weren't deliberately avoiding compliance with GDPR. She probably uses the word "mitigating". Because of the "mitigating factors" they decide the penalty will be only 2% of your annual revenue or 325 Million Euros (instead of the maximum 4%)

But the damage is done. That low level marketing manager is gone, but because of the negative press, your EMEA revenue drops a startling 18%, you miss earnings, and your stock drops 35% over the ensuing months. Now Carl Icahn and Greenlight Capital have put up their own slate of board members and they've indicated they intend to take your company private. 1000s of people lose their jobs.
How is this possible?
This story is fictional, but it's a very real scenario that companies will face in the ensuing months and years. The reality is that GDPR is more than privacy notices and breach notification requirements, it's about protecting personal rights - and meeting those requirements requires highly effective processes. To be sure, updating your notices is required, but to protect your data, protect your customers, and protect your job, you need to make sure your operations can handle the processes GDPR requires.
Automation: A requirement for GDPR compliance
In part 2, I'll talk about how meeting GDPR compliance requirements can actually help your company disrupt the competition.

Hear from PrivOps's COO at Fintech South
Hear Tyler Johnson's take on GDPR and the future of Fintech

Credit: BooDigital Here: https://boodigital.com/ https://twitter.com/talksdotcoffee https://www.facebook.com/coffeeshoptalks/

Facebook: A Cautionary Tale in Data Protection
Just last week, I noted that the UK's Information Commissioner’s Office (ICO) closed its investigation into Facebook under GDPR (the EU's new data protection law) sharing personal data with WhatsApp who they acquired in 2014 when Facebook agreed that the Facebook and Whatsapp platforms would not share data.
At the time I noted that this was a great example of GDPR's strategic company risk. Sharing customer data is usually one of the primary reasons for M&A; without it, the value of such transactions is often dramatically reduced. I wonder how many CFOs are accounting for GDPR strategic risk in their M&A strategy. Probably not many.
Wow that was quick - It just got much worse for Facebook

I just watched Mark Zuckerberg's mea culpa about the Cambridge Analytica breach on CNN. I believe he's "really sorry", there's no question his company is real trouble.
But did the activity carried on by Cambridge Analytica's Facebook user data constitute a security breach? In this case, hackers didn't compromise either FB or Cambridge Analytica, so one would have to argue that no, it wasn't a security breach.
A new concept (for some): PRIVACY BREACH
In the US, the laws governing privacy are weak to non existent. We're used to privacy notices being buried; an extensive data brokerage market exists where companies are free to sell your personal data for practically any use, including how much you pay for services, what job interviews you get, what ads you see and so on.
CIO.com: Inside the Shadowy World of Data Brokers
But as Facebook is about to discover, that doesn't mean there isn't legal risk. Lawsuits have already been announced. It's clear Facebook's troubles are just beginning.
For data privacy in the EU, things are quite different. There's no question that Cambridge Analytica's use of is a clear violation of GDPR. Ireland and the UK have already both opened investigations. The fines are likely to be tame since GDPR doesn't go into enforcement until May, but it's a near certainty EU regulators will find other ways to enforce a maximum penalty of 4% of Facebook's $40 Billion (about $1.6 Billion) . This pales in comparison to their brand risk, not to mention the risk the other 3rd parties have retained personal data scraped from Facebook and put (or will put) that information to use.
What's your risk that 3rd parties retained personal data your company gave them?
How may EU citizens are likely to stop using Facebook altogether? To understand this, let's talk about the EU consumer, and the cultural forces driving GDPR.
For many in the EU data privacy = Freedom
It's been explained to me that Europeans have a cultural memory of the Nazi "surveillance state" and this is one of the primary reasons why Europeans take data privacy so seriously (EU friends, would love your thoughts below on this) GDPR is notable, not because of the hefty fines, but because it makes control of personal data an individual right.
The Facebook Cambridge Analytica privacy scandal is sure to strengthen this perception because of the Trump campaigns' use of personal data to manipulate voters (Democrats, you're not off the hook either - see this article). This makes the likelihood of GDPR action against US companies much more aggressive than it otherwise would have been.
What can the US companies learn from the Facebook scandal?
While Facebook's situation is extreme compared to most US companies at present, most companies collect significant amounts of sensitive personal data, and with that comes significant responsibility, and risk.
GDPR is a major risk for companies with EU customers (or who otherwise handle EU resident data), but as the Facebook situation clearly demonstrates, it's not just regulatory risk and it's not just in the EU.
On one hand, we need this data to do a better job creating products and experiences customers want. On the other hand, handing such data in a consistent secure manner company wide is very difficult, especially when that data lives in many places and with 3rd parties. Companies that engage in M&A activity are especially at risk because their personal data is often fragmented across hundreds (or even thousands) of data silos.
Compliance with GDPR is a good start. If Facebook had automated data governance in place that fully complied with GDPR (including controls for 3rd party access like Cambridge Analytica) , their risk would have been much lower. If you'd like to know more about data governance automation for GDPR, look here.