
PrivOps saves you on Lakehouse, cloud and headcount costs
Cost Savings
Cloud vendor SW licenses
Cloud vendor infrastructure
Automation and usability
Number of headcount
Cost per headcount
What is the PrivOps Matrix Data Fabric?
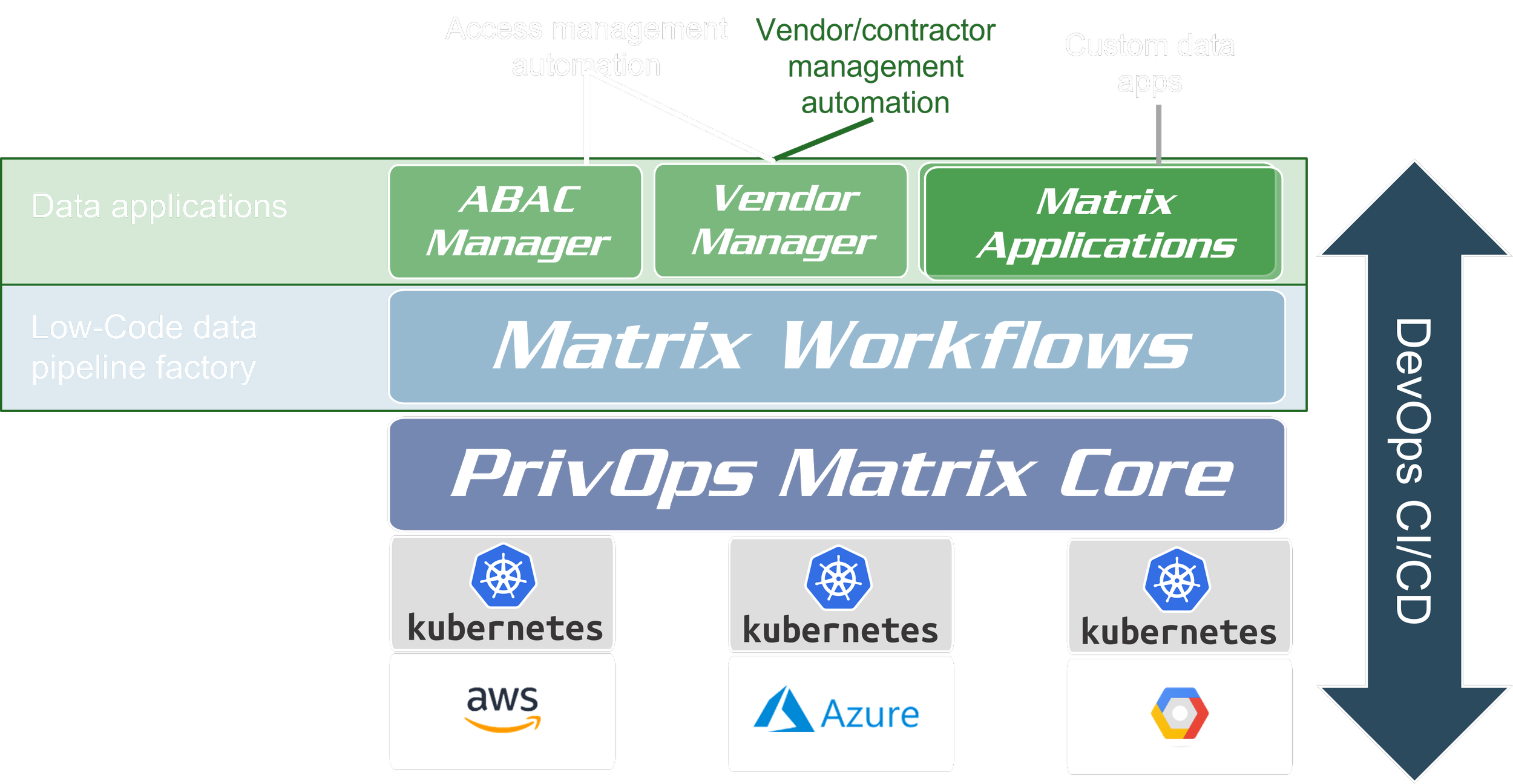
The PrivOps Matrix is a composable, real-time orchestration and governance system for data, applications, and infrastructure. Unlike static, reactive models, it enables live policy enforcement, dynamic workflow execution, context-aware data transformation, and AI-triggered automation—all from a unified, cloud-agnostic control layer.
AI-ready: PrivOps makes data integration both programmable and executable.
At its core, the Matrix encodes policy, structure, system state, and relationships into a machine-readable model that serves as a cross-platform single source of truth. Systems and agents—both human and AI—can interpret and act on it, geometrically accelerating the automation of governance, access control, and the delivery of clean, compliant data at scale.
Matrix Architecture

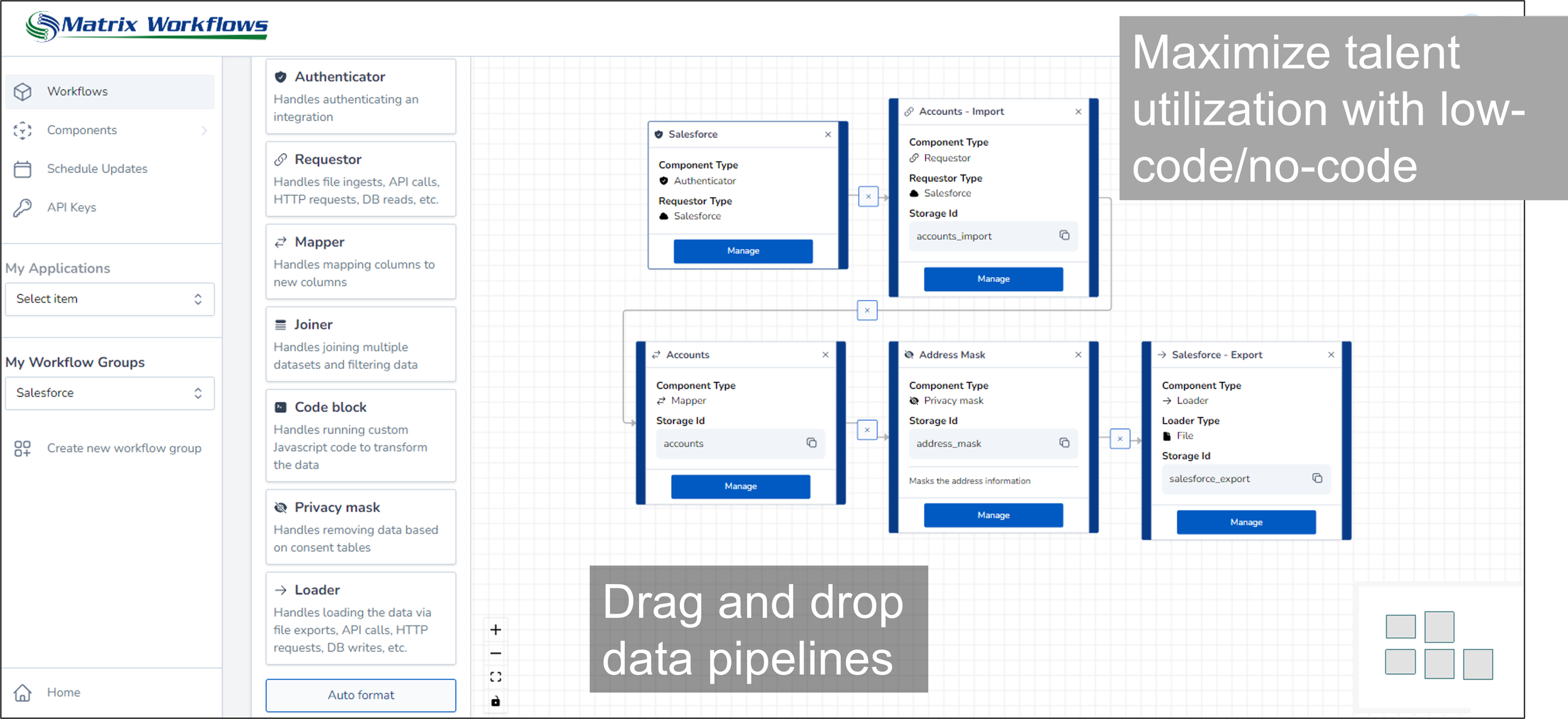
Imagine being able to reconfigure data pipelines automatically based on security breaches, changes in cloud pricing, data location, application performance, requestor identity or a host of other situations. Each data pipeline is composed at run-time based on predefined policies. This makes it possible to reuse and share data pipeline components across data pipelines as well as reconfigure data pipelines in real-time. As the data pipeline operates, a decision engine loads different application policies and data dependent on external events and state. This takes data pipeline adaptability to a new level.
Get control back from proprietary cloud and IT tools vendors by owning your data. You choose what tools to use, switch vendors as needed, accelerate integrations and automations with modular, reusable components, and reduce cost with an integration approach that scales.
Data On-demand
Any data, anywhere
Create tens, hundreds, or thousands of data pipelines to create a virtual view of your entire organization’s information. Easily share data across organizations. With the PrivOps Matrix™, you extract & process the data only when you need it. As a result, you only touch 5-10% of the data you would have stored in a traditional data lake and reduce infrastructure costs by not needing to process, replicate, or transmit the 90-95% of data you don’t need.