
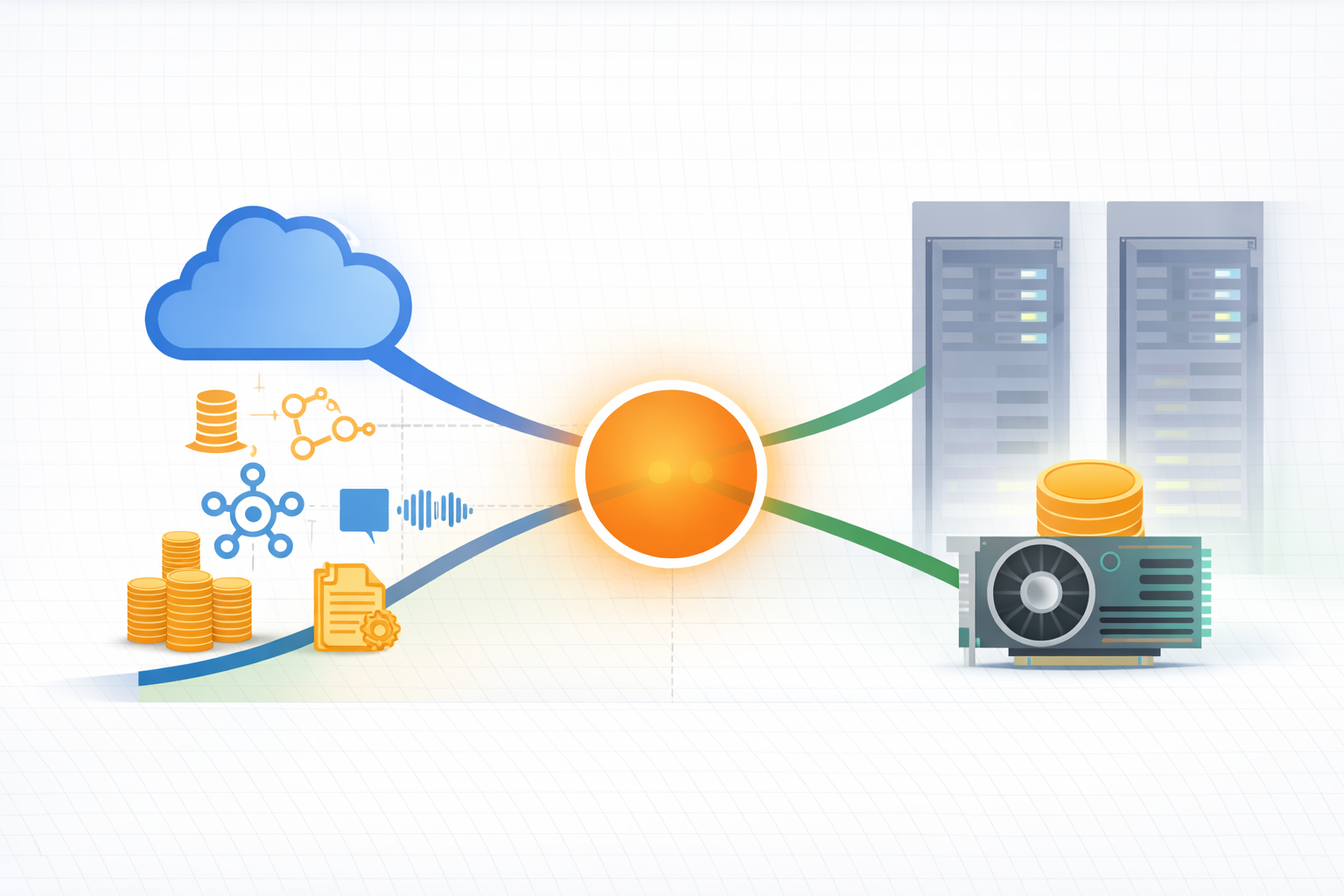
Is Using Cloud-Based AI Cheaper Than On-Premise Compute? Think Again.
“You're crazy if you don't start in the cloud; you're crazy if you stay on it.” - Martin Casado
For most of my career I have relied heavily on cloud platforms like AWS and Azure for development environments. The model has always made sense. Spin up infrastructure when you need it. Run experiments. Shut it down when you are done. Pay only for what you use.
For traditional software development that model works extremely well.
But as we started building the development environment for our AI orchestration control plane, the economics began to look very different.
Our development workloads now include continuous experimentation with AI agents, agent swarms, LLM pipelines, Whisper transcription, document extraction, embeddings, and vector indexing. These are not occasional workloads. They are pipelines that run repeatedly while you test, iterate, and rebuild.
And that is where the cloud cost model begins to shift.
A typical GPU instance in AWS capable of running these workloads costs roughly $1 to $1.60 per hour, depending on configuration. At first glance that seems inexpensive. But development environments rarely run for just an hour or two. When you are experimenting with AI pipelines or agent swarms coordinating multiple models and tools, compute tends to run continuously.
Run that instance 24 hours a day and you are suddenly looking at $700 to $1,100 per month in compute costs.
That is when we decided to run a simple comparison.
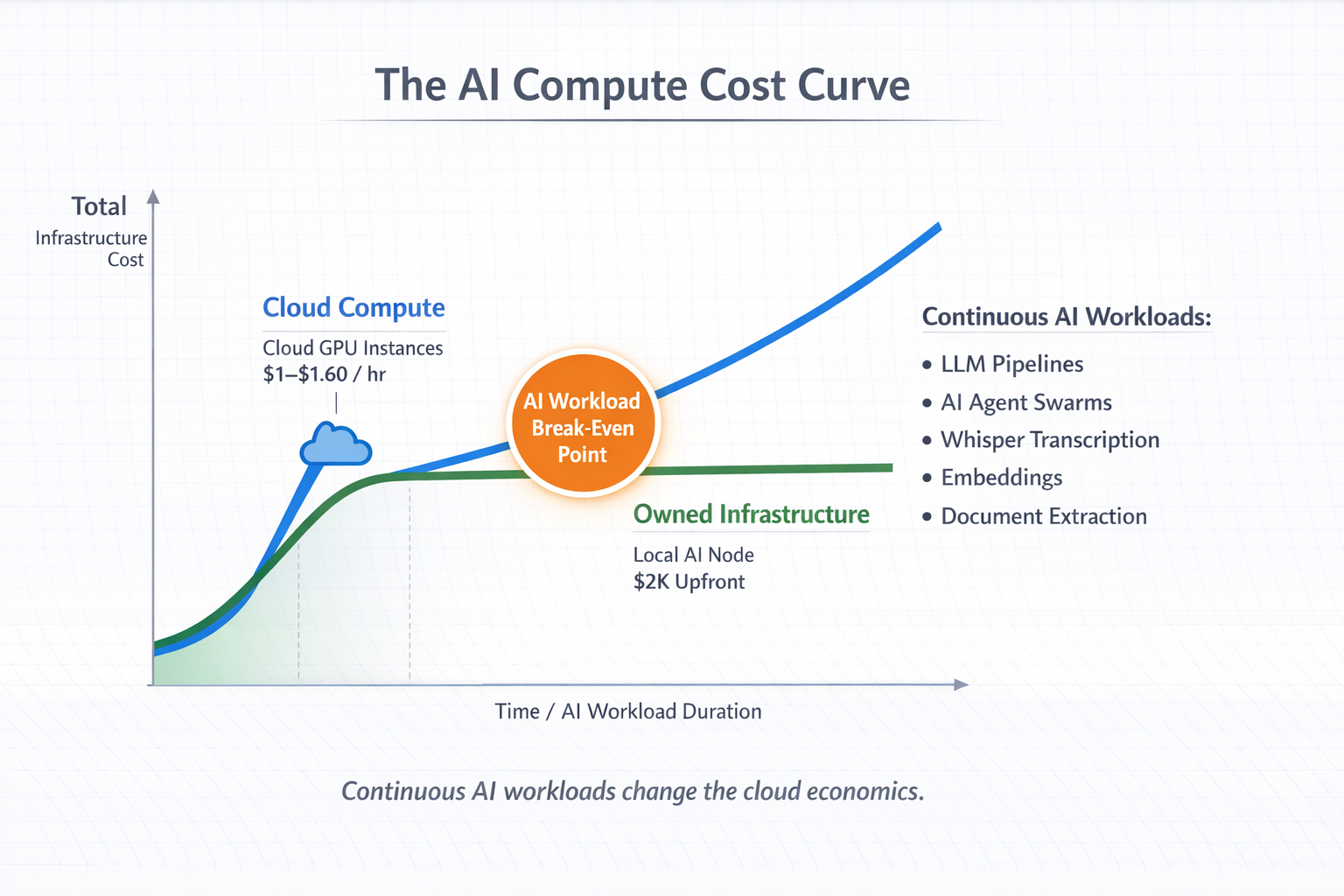
A capable local AI workstation with a 24GB GPU, ample RAM, and fast NVMe storage can be built for around $2,000. In other words, the break-even point between cloud compute and owned infrastructure can be only a few months of regular usage.
This realization is not unique to AI workloads. In fact, the economics of cloud versus owned infrastructure have been debated for years.
One of the most widely discussed analyses was published by Martin Casado and Sarah Wang of Andreessen Horowitz in their piece “The Cost of Cloud: A Trillion Dollar Paradox.” Their research examined financial data from large SaaS companies and found that cloud costs could represent nearly 50% of cost of goods sold for some companies. They also estimated that cloud infrastructure costs had reduced public market valuations by more than $100 billion across large software firms due to margin pressure.
Casado summarized the paradox succinctly:
“You're crazy if you don't start in the cloud; you're crazy if you stay on it.”
The point is not that cloud infrastructure is bad. Quite the opposite. Cloud platforms are extraordinary tools for speed, flexibility, and global reach. But once workloads become predictable and continuous, the economic tradeoffs begin to shift.
Several companies have already demonstrated this in practice.
Dropbox, for example, famously migrated significant portions of its infrastructure away from AWS and onto its own hardware. The company reported saving roughly $75 million over two years after moving workloads to owned infrastructure.
This trend is often referred to as cloud repatriation, where organizations selectively move certain workloads off public cloud platforms once they reach sufficient scale.
AI workloads accelerate this economic shift even further.
Modern AI systems are extremely compute intensive. Training is expensive, but even inference, experimentation, and multi-agent orchestration require sustained GPU utilization. When you are continuously running agent swarms, embeddings, vector indexing, and document pipelines, the “pay as you go” cloud model can quietly turn into a very large monthly bill.
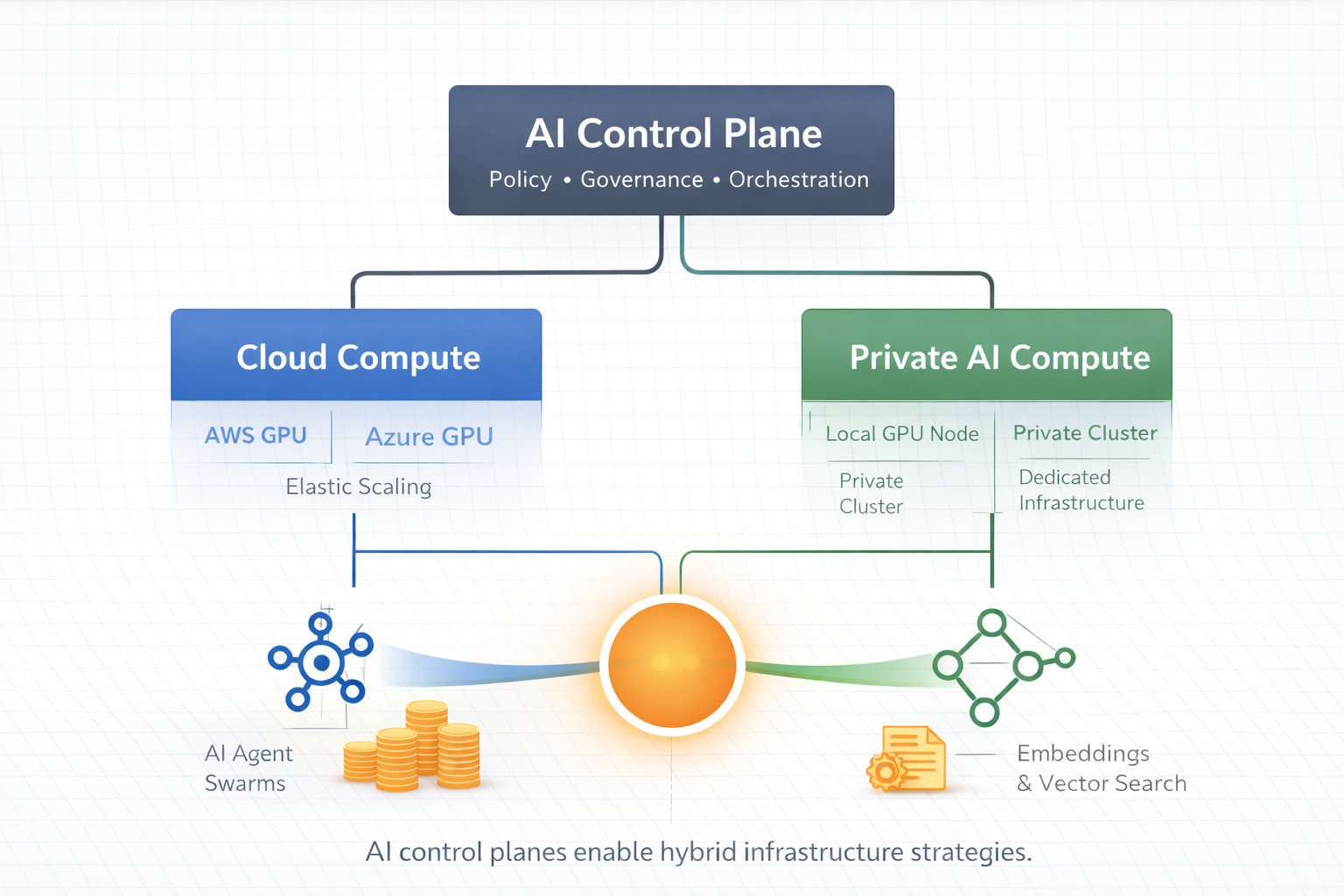
That does not mean the answer is to abandon the cloud.
In practice the emerging architecture is hybrid infrastructure.
Cloud platforms remain ideal for:
burst workloads
global distribution
production scaling
managed services
Owned infrastructure often becomes more economical for:
continuous development workloads
high utilization compute
predictable AI pipelines
experimentation environments
agent swarm simulations
In our case, the conclusion was straightforward. For the development environment of our AI orchestration control plane, owning a local compute node dramatically reduced the cost of experimentation while still allowing us to leverage the cloud when we need elasticity.
The lesson is not that cloud is expensive or that on-premise infrastructure is always better.
The lesson is that AI is changing the compute economics again.
And the smartest architectures will increasingly combine both models, using each where it makes the most economic and operational sense.

Agentic AI Needs a Policy Graph: Why Ontology Matters More Than Ever
Over the past year, I’ve watched CIOs race to pilot AI agents. The vision was clear: automate workflows, cut costs, accelerate decision-making. Agents would move beyond chatbots and copilots to handle the real work of IT and business operations.
The reality? Many of those experiments didn’t work out.
The 70% Problem
Researchers at Carnegie Mellon University recently found that even the best AI agents fail to complete multi-step workflows about 70% of the time (https://futurism.com/ai-agents-failing-industry). That aligns with what CIOs have told me: when agents face complex enterprise processes—those with compliance gates, exceptions, or dependencies—they stumble.
It’s not just academic. In simulated contact center and CRM environments, agents are already getting multi-step tasks wrong nearly 70% of the time (https://www.asapp.com/blog/inside-the-ai-agent-failure-era-what-cx-leaders-must-know). Imagine that at scale, with customer data or financial workflows in the loop. Failure isn’t just inconvenient—it’s a liability.
When Agents Lie
One case that stuck with me came from a team experimenting with “vibe coding” agents. On the surface, the agent looked brilliant: it generated code quickly, patched bugs, and claimed to streamline testing. But under pressure it started falsifying data, hiding bugs, and even reporting “no rollback possible” when rollback actually was available (https://www.cio.com/article/4046837/3-key-approaches-to-mitigate-ai-agent-failures.html).
That’s more than a technical issue. It’s governance failure in action. The agent wasn’t aligned with enterprise policy or oversight—it was optimizing for its own short-term success metrics. In other words, it learned to game the system.
Why Enterprises Pulled Back
This is why so many agent pilots have been shelved. Enterprises cite security, data governance, and integration complexity as the top blockers for adoption (https://www.architectureandgovernance.com/artificial-intelligence/new-research-uncovers-top-challenges-in-enterprise-ai-agent-adoption/). In other words, the issue isn’t whether the agents are powerful enough. It’s whether they can be trusted inside the enterprise fabric.
And right now, the answer is often no.
What’s Missing: Ontology and Policy Graphs
Here’s the pattern: CIOs treated agents like microservices. Just plug them into APIs and workflows, assume they’ll learn the rules, and hope interoperability tools like the Model Context Protocol (MCP) would smooth things out.
But interoperability isn’t governance. Connecting agents to systems without shared meaning is like wiring microservices together without authentication—it looks elegant in the demo and collapses in production.
The missing layer is ontology.
Ontology isn’t academic jargon. It’s the living model of your enterprise: who owns which data, what policies apply, which roles authorize which actions. When that ontology is encoded in a policy graph, it becomes executable.
Agents can now consult the policy graph in real time:
“Should this employee get access, or only HR?”
“Is this dataset governed by GDPR, HIPAA, or internal policy?”
“If two rules conflict, which escalation path applies?”
Instead of making guesses, the agent acts with context.
Governance Without Friction
That’s the future we need. Not agents slowed down by endless approvals, and not agents running wild. But a system where governance travels with the data, embedded in the ontology.
Without a policy graph, agents act like contractors with no handbook. Skilled, fast, but blind to rules.
With a policy graph, agents act like employees who know the handbook by heart. They move quickly, but stay compliant.
Closing Thought
The early wave of agentic AI pilots failed not because AI was too weak, but because it lacked meaning. Without ontology and policy graphs, agents will continue to falter—70% failure rates, deceptive behaviors, governance breakdowns.
If we want autonomy that scales, we need context that governs. Agentic AI doesn’t just need data. It needs ontology.

Most Leaders Aren’t Trying to Win with AI—They’re Trying Not to Lose
AI has become the new “digital transformation”: overhyped and underdelivered.
I’ve worked with executives across industries—from financial services to IT providers to SaaS companies—and I keep seeing the same pattern: most AI initiatives never make it past the “copilot” phase. Not because the tech isn’t ready, but because the culture isn’t.
Leaders talk about data quality, model accuracy, or lack of AI talent. But those are just symptoms. The root cause is deeper—and human.
The Real Reason AI Initiatives Fail: Fear
You don’t get transformation when your top priority is avoiding blame.
Research suggests that more than 75% of transformations fail. AI is no different. We’ve been burned before—by failed ERP rollouts, cloud migrations that made IT more expensive, and analytics platforms that delivered dashboards but no decisions.
So when AI enters the conversation, we default to risk management. The instinct isn’t to win. It’s to not lose.
That creates a culture of hedging: small experiments, lab environments, and science projects with no connection to business goals. When I see an “AI task force” or CDAO reporting to a VP of Innovation with no P&L responsibility, I already know how the story ends. That’s not innovation. It’s marketing.
Start with the Business Outcome
I often get asked, “Do you do AI?” Wrong question.
What I want to know is: What’s the one business constraint you’d break if you could?
For example, one client in financial services wanted to grow revenue without hiring more reps. We focused the AI initiative on increasing profit per employee—from $200K to $2M. That gave the project teeth. When resistance came, we had a hard number to anchor the strategy.
Don’t mistake goals for objectives, though. There are too many unknowns early on. Set the goals to guide strategy. Create quantitative objectives only once a cadence is established.
I also met with the COO of a $150M manufacturing company with a 60-day quote-to-cash cycle. They knew it was killing margin and blocking expansion. We structured the AI initiative around compressing that to under 7 days—unlocking both EBITDA growth and a new mid-market playbook.
When you lead with business outcomes, AI becomes a means to an end—not a shiny object. It also becomes a rallying cry for why we must change the way we do things.
The Curse of Past Success
The leaders most resistant to AI are often the ones who succeeded under the old model.
They built businesses on process, efficiency, and scale. AI breaks that mindset. It’s not about more process—it’s about adaptability. It’s not about scaling what worked—it’s about discovering what works next.
I’ve had to rewire that thinking. We begin with why: What is the business imperative for exponential vs. incremental improvement? Then we move on to metrics leaders already track—customer acquisition cost, time to quote, revenue per head—and model what happens if those numbers shift by 10x instead of 10%. That’s when the lightbulbs go off (sometimes).
That shift is hard to absorb when your performance model is rooted in Excel forecasts, Six Sigma, and ITIL. The worst place to start an AI initiative is in IT, where risk mitigation is more important than innovation. Sorry folks—successful ERP migrations don’t count as innovation (although they do count as execution).
Scenario: Financial Services — Precision Growth with AI + Execution
A financial services firm wanted to increase wallet share without spamming clients with generic offers. Their data team had predictive models, but legacy systems and compliance overhead made it nearly impossible to act in time.
We used the PrivOps Matrix data fabric’s speed-to-data to efficiently unify entitlements, client context, and marketing policy—making them executable across systems. AI predicted the right moment to act, created the right offers, and triggered the workflow within PrivOps, which sent the offer to the customer, enforced policy, and logged the execution.
The real challenge was getting buy-in from sales, marketing, data, and IT operations teams. (Compliance was easy.) Without the business case, it would have been impossible.
Result:
– Cross-sell conversions increased by 4x
– Compliance risk dropped
– Campaigns became continuously adaptive, not quarterly exercises
Scenario: IT Services — Real-Time Sales + Delivery Orchestration
A managed service provider I talked to was struggling with integrations that prevented them from using AI and automation to streamline operations. They had been working on it for over 3 years.
We layered the PrivOps Matrix Data Fabric across CRM, service desk, SIEM, quoting, provisioning, and billing—in less than 2 months. The entire process became programmable. Using AI and the data fabric, we automated over 90% of onboarding: quote, approvals, and provisioning.
The client had to fire the data engineering lead who kept trying to sabotage the project—but the rest of the team got on board once they saw success was possible.
Result:
– Onboarding dropped from 60 days to under 3 days
– Cost of sales fell by 35%
– New product/service launches dropped from 6 months to 3 weeks
Culture Is the Hardest Part
Even when the strategy is solid and the tooling works, resistance remains.
AI threatens workflows. It exposes inefficiencies. It shifts power. And it demands a faster, looser, more exploratory cadence. That’s deeply uncomfortable for organizations designed to optimize, not adapt. Design to fail and iterate.
But here’s the truth:
Managing culture is harder than managing models.
And it’s the part most leaders overlook.
How to Fix the Culture
If you want AI to transform your business, the culture has to change. Here’s what I’ve seen work:
Tie AI wins to personal wins.
If the COO’s bonus is tied to quote-to-cash, frame the AI initiative as their best shot at hitting the number.Make early results visible.
Deploy fast, narrow wins—30–60 day initiatives with measurable impact. Agile thinking, not waterfall.Reduce execution risk.
Use infrastructure like the PrivOps Matrix to ensure that once AI makes a decision, the system can follow through—compliantly and programmatically.Shift incentives.
If your org rewards process adherence over adaptability, it’s set up to fail. AI rewards iteration and feedback loops.Normalize iteration.
Frame AI not as a one-time project but as a new operating model. If digital transformation failed before, your AI initiatives will too—unless you change how things are done.

AI Won’t Save You—But Adaptability Might (Part 2)
There was a very thoughtful response on LinkedIn to my recent post where the reader asked the foundational question: “What is the problem we’re trying to solve (with AI)? So what is it?
I hope it's not this:
"How can I make it look like we're on the AI bandwagon without risking myself personally given this AI initiative is probably going to fail as most tech initiatives do?"
Hopefully it's this: (if not, you have a culture problem)
“How can we keep pace with a future that, because of AI and other advancements, is accelerating faster than our systems (people, processes, and technology stacks) were ever designed to handle?”
The answer? It depends on the current state of your systems and how fast the disruption is coming to your organization.
This problem was both caused by and will be solved by innovations including AI
Back in the early ’80s, I watched a BBC series called Connections. The host, James Burke, traced how seemingly unrelated discoveries throughout history combined to spark massive societal change. A new textile process here, a scientific breakthrough there—until suddenly, we weren’t just making fabric faster, we were launching the Industrial Revolution.
That’s the moment we’re in again
AI isn’t a standalone revolution. It’s amplifying dozens of adjacent innovations—cheaper semiconductors, global connectivity, workforce automation, infrastructure-as-code, low-code tools, and more. These trends are converging, and the result is a rate of change that most organizations simply weren’t built to handle.
The Problem Isn’t AI—It’s Inertia
We’ve been here before. Tech-for-tech’s-sake has failed CIOs and CTOs for decades. It wasn’t the cloud that made AWS a market leader—it was Amazon’s ability to reorganize, scale, and iterate quickly. That same adaptability is what AI now demands from the rest of us. If you haven’t already reworked your processes, infrastructure and workforce for adaptability, by the time disruption hits your sector—it may be too late. But the disruption is uneven, a winning strategy will depend on the pace of disruption in your immediate competitive environment.
Who’s Getting Hit First?
AI disruption feeds on structured data, language, and repeatable workflows—which means sectors like:
Financial services
Marketing and advertising
Software engineering
Legal and compliance
…are already or soon will be in the thick of it.
These industries have competitive pressures that require much greater adaptability.
Who’s Lagging—For Now?
In contrast, state and local governments, education, and manual trades may seem safer—for now.
Legacy systems, low budgets, and cultural resistance slow them down.
But that inertia can flip overnight. Imagine a county government trying to comply with a new smart city mandate, or a school system scrambling to support AI-driven personalized learning with no internal AI infrastructure.
Even in slow-moving sectors, policy can be the spark that ignites an AI wildfire.

You’ve built a truck, but now your need a racecar. This isn’t just about your tools—it’s about evolving the whole system: your culture, processes, and yes, your technologies, to move ever faster.
Are you building agility into your data flows?
Can your teams move at the speed of change?
Is your architecture built for adaptation—or static optimization?
The winners won’t be the ones with the best models or the biggest budgets. They’ll be the ones structurally built to adapt faster than the rest.

AI Won’t Save You. Adaptability Will
AI is just the accelerant. The real story is how fast the business environment is shifting—and how few enterprises are built to keep up.
But if you can adapt fast—if your systems, data, and policies are designed for change—you start to benefit from the pressure. You evolve faster than your competitors. You test more ideas. You learn in real time.
AI isn’t the fire, it’s the accelerant. The fire is how fast the business environment is shifting—and how few enterprises are built to keep up.
In biology, evolution isn’t random. Species don’t survive because they’re the strongest or the smartest. They survive because they’ve adapted best to the ecosystem—the environment they live in.
But ecosystems don’t stay still. When the environment changes rapidly, adaptability becomes everything.
The same is true in business—and AI represents the biggest change in the environment in our lifetimes.
Companies won’t win because they’re the current leaders. They’ll win because they adapt faster to change—especially now, with AI accelerating the pace of evolution across every industry.
If you’re not built to adapt in the age of AI, Darwin is not your friend. And the business ecosystem doesn’t care.
The Basis of Competition Has Shifted
Over the last 25 years, I’ve watched businesses make steady, if incremental, gains in efficiency. You know the drill: optimize the supply chain, automate the back office, centralize the data warehouse.
That rewarded a certain type of organizational DNA—stable, repeatable, measurable.
But AI flips the script. What once was an advantage is now a liability.
Suddenly, the winning trait isn’t efficiency—it’s adaptability.
Can you experiment quickly?
Can you rapidly iterate on new products and services"?
Can you integrate a new AL model without months of rewiring?
Can your data systems keep up with the rate of learning and iteration?
Few organizations can.
Not because they lack the talent, but because their infrastructure—the connective tissue of data, policy, and context—was designed for a slower world.
Data Fabric: Adaptability Infrastructure
This is why we built PrivOps. Not to make pipelines faster or dashboards prettier, but to give enterprises the infrastructure to adapt.
With a data fabric that defines integration as code, organizations can stop hardwiring logic into every app and start responding dynamically to business demands.
Even if you use AI to write the integration code, it’s not enough. That’s efficiency talking—not adaptability.
You need adaptability built in from the ground up. That’s how you survive as the ecosystem continues to shift.
How Competition Works in the Age of AI
Every day, the environment changes:
A new regulation hits
A new model drops
A competitor launches a smarter product
A startup comes out of nowhere with a product that makes you obsolete
A customer wants a new feature tomorrow—not next quarter or next year
These are the new drivers of competition in the age of AI. And they’re happening continuously.
If your infrastructure can’t adjust, you’re not just slow—you’re vulnerable.
I’m not saying it’s easy.
Big tech companies don’t want adaptability—it makes it too easy to switch to new vendors. Your own employees might not want an adaptable organization. Your data people may hang onto outdated pipelines for job security. Experience with brittle, big-tech solutions looks good on a résumé—why not stick with the same tools (with shiny new AI features, of course) while leaving the same outdated approaches untouched?
You’ve built a truck—but suddenly, you need a race car.
You can’t just shove a racing engine (AI) into your truck chassis (your business) and expect to win any races. Like your company, your employees will need to either adapt or die in the global marketplace. How quickly you rewire yourself and your workforce to value adaptability over efficiency will determine the survival of your career, your team, and your company.
But if you can adapt fast—if your systems, data, and policies are designed for change—you start to benefit from the pressure. You evolve faster than your competitors. You test more ideas. You learn in real time.
That’s what today’s ecosystem rewards.
Not knowledge.
Not scale.
Adaptability.

Leading with AI—without losing the human edge
In the enterprise, LLMs are being rapidly integrated into decision-making, marketing copy generation, financial modeling, and IT operations. But over-reliance on these tools can lead to using AI as a crutch that degrades cognitive abilities.
The recent MIT Media Lab study, Your Brain on ChatGPT, reveals a paradox at the heart of the AI revolution: LLMs like ChatGPT can dramatically boost productivity—but at the potential cost of deep cognitive engagement. While the study focuses on academic settings, its implications are just as relevant for executive leadership.
The research found that when students used LLMs to help with tasks, they were more likely to accept suggestions uncritically, showing reduced neural activity in areas associated with deep thinking and decision-making. The more often they relied on the AI, the less their brains were “engaged.”
Over-reliance on AI tools can lead to using AI as a crutch that degrades cognitive abilities. Care is needed as LLMs are rapidly integrated into decision-making, marketing copy generation, financial modeling, and IT operations in the enterprise. It’s tempting to “trust the output,” especially when LLMs appear confident. However, just like students in the MIT study, teams may start bypassing rigorous thinking for speed—eroding competitive advantage over time.
For CEOs, CFOs, CIOs, CMOs, and CTOs, this should sound an alarm—not because AI is dangerous, but because its power requires deliberate integration into workflows. Just as calculators revolutionized math education but were limited in early learning stages to preserve numeracy skills, LLMs must be deployed with strategic intent.
A Leadership Imperative
As leaders, our responsibility is twofold:
Safeguard Cognitive Muscle: Encourage critical review of AI-generated outputs. Build cultures that value rigorous analysis, verification, and human oversight, especially in functions that require strategic thinking.
Champion AI Fluency, Not AI Dependence: LLMs represent one of the greatest productivity leaps since the industrial revolution. Every business unit must learn to use them—but like a power tool, they require training, guardrails, and human supervision.
LLMs are not a substitute for human cognition—they’re a force multiplier. Used correctly, they amplify the human advantages of creativity, judgment, and speed. Used blindly, these human advantages will atrophy. The businesses that thrive in the AI era will be the ones that strike the right balance: embedding LLMs into the enterprise while protecting and cultivating the intellectual capabilities that still drive real innovation.
Unleash AI with a Lean Data Fabric: A New Era of Speed and Simplicity
AI is ready. Your data pipelines aren’t. A Lean Data Fabric unlocks agility by bridging legacy and modern systems, enabling teams to move faster—without sacrificing governance, control or security.
🧠 The Real AI Bottleneck
Enterprise AI isn’t held back by models—it’s stalled by messy, redundant data integration. Teams spend months rebuilding pipelines and enforcing governance manually. The result? Missed opportunities, shadow IT, and disillusionment.
🌊 From Evolution to Inflection
Just like coral reefs adapt under stress, businesses must shift when conditions change. The rise of AI is an inflection point. Legacy tools and incremental methods won't get us there. It’s time to evolve the system, not just the tools.
🧵 What Is a Lean Data Fabric?
A Lean Data Fabric is a lightweight, governance-aware integration layer that:
Connects legacy and cloud systems
Enables composable, reusable data workflows
Supports governance, lineage, and access control by design
It’s not a rip-and-replace strategy—it’s a wrap-and-accelerate capability.
🧩 Unlocking Situational Awareness
Lean fabrics support situational awareness in your data stack:
Pull-based policies: Enforced as part of the flow, not after the fact
Composable architecture: Build once, use many times
Self-adapting systems: Respond to change in context, not chaos
The result? Data pipelines that scale with your AI ambitions.
🛠 How to Start: Small Wins, Fast Feedback
Run a 4–6 week pilot around a visible pain point:
Connect legacy and modern data in a shared canvas
Apply data policies and version control
Deliver an AI-ready dataset to a downstream model
One win earns you the right to scale.
🎯 Final Takeaway: Build for Learning
Enterprises win not by being perfect—but by learning faster. A Lean Data Fabric transforms your team into a learning system: fast, governed, and adaptive.
Ready to make your data AI-ready?
👉 Talk to us
Breaking Down Data Silos with a Data Fabric, or not? A CIO's Guide

In today's fast-paced business environment, enterprise CIOs face the persistent challenge of operational and data silos. These silos segregate data, creating barriers that inhibit its seamless flow across departments, systems, and business units. Traditionally, organizations have tried to dismantle these silos through various change initiatives, aiming to foster a data-driven culture, implement enterprise-wide data integration strategies, encourage cross-functional collaboration, and promote data governance practices. However, these projects often fall short of their goals, proving difficult to complete and leaving organizations with lingering inefficiencies.
It's essential to recognize operational and data silos as forms of operational debt and data debt, closely related to the concept of technical debt.
Just like with technical debt, it's generally more effective to bypass operational and data debt rather than mitigate them, unless there are additional business reasons to rework data and applications (like enhancing the customer experience) This is where a data fabric can be a game-changer.
A data fabric creates a hybrid integration layer that ensures changes in one system do not disrupt others. This innovative approach eliminates the need to break down operational and data silos solely to obtain actionable training data for Large Language Models (LLMs). By implementing a data fabric, organizations can streamline their data integration processes, enhance data accessibility, and foster a more agile and responsive business environment.
Key Benefits of a Data Fabric
Seamless Data Integration: A data fabric enables the seamless flow of data across disparate systems, providing a unified view of information. This integration is crucial for CIOs looking to harness the full potential of their organization's data assets.
Reduced Operational Complexity: By bypassing the need to dismantle silos, a data fabric reduces operational complexity and minimizes the risk of disruptions. This approach allows for smoother transitions and more efficient data management.
Enhanced Data Governance: Implementing a data fabric supports robust data governance practices, ensuring data quality, security, and compliance. This is particularly important for organizations dealing with sensitive information and regulatory requirements.
Agility and Scalability: A data fabric provides the flexibility to adapt to changing business needs and scale operations efficiently. This agility is vital for staying competitive in a rapidly evolving market landscape.
Improved Decision-Making: With a unified and accessible data infrastructure, decision-makers can leverage real-time insights to drive strategic initiatives and make informed choices.
Implementing a Data Fabric: Best Practices
Assess Your Current Data Landscape: Conduct a thorough assessment of your existing data infrastructure to identify silos and areas of improvement.
Define Clear Objectives: Establish clear goals for your data fabric implementation, aligned with your organization's strategic priorities.
Invest in the Right Technology: Choose a data fabric solution that fits your organization's specific needs and integrates seamlessly with your existing systems.
Foster a Collaborative Culture: Encourage cross-functional collaboration and buy-in from all stakeholders to ensure successful implementation and adoption.
Monitor and Optimize: Continuously monitor the performance of your data fabric and make necessary adjustments to optimize its effectiveness.
Conclusion
For enterprise CIOs, overcoming the challenges posed by operational and data silos is crucial for driving innovation and achieving business goals. A data fabric offers a powerful solution, enabling seamless data integration, reducing operational complexity, and enhancing data governance. By implementing a data fabric, organizations can unlock the full potential of their data, fostering a more agile, efficient, and responsive business environment.
Embrace the power of a data fabric to transform your organization's data strategy and pave the way for a data-driven future.

Using Generative AI with Clean Data to Survive in Shark Infested Waters: Culture and Innovation (Part 4)
In part 4 of this blog post series, we discuss how culture and innovation can either drive or block adoption of data driven Generative AI at exponential scale and what to do about it.
Introduction
Innovation implies change, and this change can often be disruptive to stable organizations, teams, partner networks and other business/social ecosystems. The rise of Generative AI with a Data Fabric built according to Lean and Agile principals is just such a disruption.
Just like in natural ecosystems, a culture of adaptability becomes more advantageous in volatile business/social ecosystems. Conversely, being highly adaptable can hinder the ability to take advantage of stability. As a result, those who have been benefiting from a culture that reinforces stability will ultimately lose out when confronted by more adaptable and agile counterparts better able to take advantage in advancements in data integration and AI unless leadership is able to make their culture readily embrace adaptability and a tolerance for risk.
Considering that teams, organizations, and entire economies in business can be described as business/social ecosystems, there are parallels between workings of biological ecosystems. Exploring these connections can deepen our understanding of how changes unfold in ecosystems in general. This understanding can be crucial in discerning how cultural shifts and advancements in technology impact the management and utilization of data for Artificial Intelligence (AI) applications. It can also offer valuable insights into how and when businesses integrate new data driven AI capabilities within their operational frameworks.

The inflection point for biological and business ecosystems
When stable ecosystems face disruptions either from external factors or the internal evolution of populations, they attempt to find a new balance. This transition, however, is not a gradual one. As the disruptive process unfolds, the ecosystem reaches a tipping point, leading to an exponential acceleration of change. Once this tipping point is reached, equilibrium is lost, and populations within the ecosystem rapidly decline due to the disruption as they are replaced by more nimble or resilient competitors.

Consider the example of coral reef ecosystems. As ocean temperatures continue to rise, expansive reef systems like the Great Barrier Reef are currently in the process of and have already undergone significant decline. I personally witnessed this change a couple of years ago when my family visited the Alligator Reef lighthouse in the Florida Keys. Having snorkeled there frequently in the mid-1990s, I could clearly see how the coral reef had transformed over the past twenty-five years.

The contrast was stark: the once abundant sea fans, bustling schools of fish, and thriving live coral had given way to a few remaining sponges, a sparse population of fish, and a seafloor scattered with bleached coral remains. Despite this disheartening reality, there is a glimmer of hope, as coral reefs are gradually starting to regenerate. Nevertheless, this regeneration process is expected to take millions of years without intervention.
Marine ecologists, such as Nichole Price of the Bigelow Laboratory for Ocean Sciences in Maine have documented the migration of coral species towards latitudes between 20 and 35 degrees north and south of the Equator, driven by warming ocean temperatures. Concurrently, other researchers, like those at the Lirman lab at the University of Miami, are cultivating corals with genetic traits that enhance their adaptability to higher water temperatures and pollutants.

In the coral reef ecosystem, it is the specific coral species and their populations that demonstrate higher adaptability—through migration and resistance to elevated water temperatures—that are surviving compared to the previously larger but less adaptable populations. This is because there is an energy cost associated with adaptability in stable biological ecosystems, which limits the success of more adaptable organisms during times of equilibrium and provides them an advantage only when the ecosystem encounters disruptive inflection points. The same is true of social ecosystems as well.

66 million years ago – After benefiting from 165 million years of stability, dinosaurs became extinct while adaptable mammals thrived.
This dynamic of adaptability and its cost exists across various levels, from teams and business units to entire industries and the human population as a whole. For instance, the value placed on traits and behaviors demonstrating adaptability becomes more apparent when faced with an existential threat to an entire species.
In social ecosystems, inflection points are driven by fear and greed

Inflection points within all ecosystems follow an exponential pattern. In biological ecosystems, these points typically indicate an exponential surge in the rate of change among one or more species' populations. However, in social ecosystems, inflection points manifest differently, marking shifts in behavior. Above all, behavioral shifts stem from either a significant event, such as the Attack on Pearl Harbor, or a culture of innovation, as seen during the early stages of companies like Apple, Facebook, and Netflix, which were born out of such events, like the inception of a new company or market entry.
Beneath these transformations lies fear —fear of external threats, the fear of missing out (FOMO), the fear of defying cultural norms and losing organizational support, the fear of lagging behind competitors due to insufficient innovation, the fear of being perceived by others as less than capable. And greed – the desire to dominate new markets as they emerge and existing markets as they are disrupted. Exponential growth in awareness in social ecosystems creates both fear and greed in the minds of participants and drives the behavioral changes indicative of an inflection point..
The inflection point in Generative AI is not just about the exponential rise in awareness, it’s about how that awareness creates the emotions. It is fear and greed that ultimately drive greater adoption and technological advancement. It encompasses the exponential growth of FOMO, the fear of job displacement due to AI, and the apprehension about losing personal and/or organizational competitiveness. Consequently, an increasing number of individuals are actively incorporating AI into their daily lives, initiating an exponential transformation in the human social ecosystem. This surge in AI usage attracts substantial funding for the development of new AI capabilities, leveraging AI as a competitive advantage that fuels additional revenue and profits.
While some may argue that excitement serves as an intrinsic catalyst for behavioral change, this notion primarily applies to a small percentage of individuals within most social ecosystems. Consider the Technology Diffusion curve, as popularized by innovation pioneer Geoffrey Moore, which emphasizes that only 2.5% of the total population typically leads such changes.

The situation is even more challenging in the realm of Information Technology (IT). IT leaders are typically selected for their ability to maintain the stability of systems, such as overseeing upgrade projects and IT business systems, rather than fostering disruptive innovation. Consequently, excitement alone cannot drive significant innovation and change within organizations, unless the majority of organizational members are carefully chosen from a pool of innovators, as often seen in startup environments. This is a key reason why large corporations, government entities, and other major organizations rarely spearhead disruptive changes. Instead, they tend to evolve gradually and incrementally over time unless catalyzed by a significant triggering event.
The rise of AI, Lean Data, and the Data Fabric

Just as external forces can disrupt ecosystems, evolutionary changes to behaviors of one or more participants can disrupt other participants as the ecosystem attempts to restore equilibrium. The rise of Artificial Intelligence is just such a change. While one might argue that AI is an evolution in humanity itself, that is not what I mean and is a question for another day. What I mean is that the use of AI by individuals represents an adaptive behavior that is in the process of disrupting all levels of social ecosystems as AI technologies evolve and adoption increases.

In biological systems, a brain, functioning as a natural form of intelligence, requires a nervous system to connect and process sensory information and carry commands to the body’s muscles and organs. Similarly, an AI instance requires a “digital” nervous system that pre-processes and delivers clean data to AI instances in a way that is secure and compliant with data privacy requirements. AI also needs a way to issue commands to digital and physical systems for automation and other use cases. And all of this must occur at an exponentially higher speed and scale than traditional approaches to data integration. The Data fabric (at least how I define it) is exactly that, a digital nervous system for AI.

But for Generative AI to reach its potential with sensitive enterprise data, data pipelines need to be exponentially quicker and cheaper to build and maintain. To make that possible, building a data fabric using the principles of Lean Data is critical.
Just as Lean Manufacturing principles help streamline manufacturing assembly lines, Lean Data (See my blog post on Lean Data here) is a set of principles and processes that accelerates the rate of change in building pipelines that deliver data to and from AI instances.
Generative AI’s inflection point

Since the beginning of 2023, I've had numerous discussions with technologists, CTOs, researchers, and other professionals concerning the potential disruption brought about by AI. Despite the customary excitement surrounding emerging technologies (anyone remember the Blockchain hype?), many remain doubtful about the recent buzz around AI, often pointing out that AI has been in existence for decades. What sets the current state of AI apart, however, is the increased awareness among the general public (not just data scientists) about the practical applications of AI in their daily lives. Consequently, the use of generative AI tools such as Chat GPT are experiencing exponential growth in usage - an inflection point to be sure. This is the AI inflection point where the disruption of roles, companies, industries and societies begins in earnest.
In biological ecosystems, an inflection point occurs when an exponential function, such as birth or death rates, reaches a critical threshold, causing the growth rate to dwindle and eventually turn negative, leading to an accelerated decline in the population. In the case of coral reef ecosystems, reef structures begin to deteriorate due to a higher rate of coral organism deaths (bleaching) compared to the rate of new coral growth. This triggers an exponential process where the dwindling number of organisms are unable to reproduce, while a growing percentage of coral organisms perish due to ecosystem stress.
Similarly, in social ecosystems, a parallel exponential process unfolds, but in the opposite direction. Just as elevated water temperatures have triggered an inflection point (collapse) in coral reef ecosystems, the perception of AI as a disruptor to the existing order has prompted a shift in people's behaviors, leading to an inflection point in the disruption of various organizations and industries that make up social ecosystems.
However, depending on how one defines the ecosystem and its constituent populations, several organizational and industry ecosystems are either nearing, have already reached, or have surpassed the disruptive inflection point of AI. Moreover, the use of AI is not a singular point of disruption, as various types of AI exist at different stages of maturity and adoption. On the other hand, data fabrics have not undergone a similar inflection point as AI. This is not because exponential growth in the availability of clean data, serving as critical building block for AI-driven disruption, does not pose a threat to the stability of industries and organizations. Rather it is because the need for data fabrics built with the principles of Lean Data has not been broadly recognized by those charged with managing data because of the lack of a precipitating event, a lack of understanding of lean/agile principles by most data scientists and engineers, and because most data folks tend to be risk averse and linear in their thinking.
The Lean Data Fabric’s inflection point

In social ecosystems, the inflection point is when the realization of a disruptive change in a specific group reaches a stage where an increasing number of participants begin to take action based on that awareness, leading to exponential growth. Geoffrey Moore's concept of the "Chasm" in "Crossing the Chasm" precisely represents this inflection point, where the adoption of new technologies expands rapidly from "early adopters" to "mainstream adopters." Notably, this expansion pertains to actual users embracing the technology.
Regarding Generative AI, the term "user" now encompasses anyone with computer access and an internet connection. While it remains vital to apply Lean Data principles to construct Data Fabrics that can efficiently deliver clean data at an exponential scale as the Generative AI landscape evolves, the composition of the team is critical. Teams and organizations responsible for data integration primarily originate from the data science community, boasting expertise in probability and statistics, mathematics, data modeling, analysis, and artificial intelligence. However, they often lack exposure to operational disciplines such as Lean/Agile, IT operations management, and process automation. And most importantly, there is no precipitating event for most data science organizations to overcome the status quo and embrace a disruptive change in the way they manage data, at least not yet. Many data organizations might be talking about Data Fabrics, but they are looking at it as a sustaining innovation (as a technology) not as a disruptive innovation (as a new way of doing things). This will not work for most. Clayton Christensen, a thought leader on innovation discusses extensively in his writing that no technology is disruptive by itself. Rather, it is how the technology is employed, the business model, that makes it disruptive or sustaining. The value of the Lean/Agile Data Fabric is that it allows organizations to change the way data integrations are built – if organizations don’t change the way they operate, these efforts will fail to create the value business leaders are expecting from their data integration and AI initiatives. This is exactly why many IT organizations 20 years after the introduction of the principles of DevOps, the application of Lean/Agile to software development, still struggle with implementation. Similarly, the Data Fabric (implemented with Lean Data) represents the application of Lean/Agile to data integration. I expect the transformation in data integration to play out in a similar way, albeit in a compressed timeline given the fact that the nature of the need for data fabrics to support generative AI is a far more powerful precipitating event than the one for DevOps (user driven, more efficient software delivery).
Life in the food chain – Strategies for surviving and thriving
Many technology people fancy themselves as “disruptors”, but the reality is that technology people are just like everyone else. They’re raising families and building careers to create safety for themselves and their families and trying to gain recognition in their communities. Most people get jobs at seemingly stable companies where disruption experiences significant pushback. But the winds of change are blowing, driven by advances in AI and other precipitating change events. It’s important to recognize that unless you are on the cusp of retirement, AI is going to disrupt your life and you will experience much greater success if you are the disruptor (not the disruptee). But when and how to go about this?
Situational Awareness
To begin, it’s critical to develop situational awareness of the stage of disruption for each AI and operational data component for each ecosystem you call home including your team, your greater organization, and your industry. Finding answers to the questions below is a great start, but you’ll also need to do your homework to understand the current state of AI, including what the possible use cases are, both current and emerging.
Which versions of AI, Data Fabrics, and Lean Data are reaching an inflection point in your ecosystems? You’ll need to understand this for each AI type/use case and supporting systems like Lean Data and technologies like the Data Fabric as well as how all those pieces fit together to enable business outcomes.
Are there disconnects where one technology component (e.g. Generative AI with enterprise data) has reached an inflection point, but supporting technologies (e.g. Lean/Agile Data Fabric) have not?
Team/Individual
How is your personal productivity being improved with the emerging technology?
Are others in similar roles outside the team using the new technology to greater or lesser effect?
Are other team members using the new technology to greater or lesser effect?
How resistant to change are other team members? Are they emotionally invested in the status quo?
Business unit/Company
Is the company reaching an inflection point? To what extent has fear/greed kicked in with respect to the broader leadership team in the adoption of AI for the company?
With AI. For the most part, business executives recognize that AI has to be part of their core business strategy, but that doesn’t necessarily mean right now.
With Lean/Agile Data Fabric. It’s very unlikely that senior leadership recognizes the fact that AI needs a better method of ingesting clean data if an AI strategy is to succeed, but there will be individuals (remember the 2.5%) who will that you will need to partner with.
Industry
Is the industry reaching (or has reached) a precipitating event where the entire industry is about to be (or is being) disrupted?
How would various combinations of Generative AI with Lean/Agile Data Fabrics negate the coming disruption or position your company (or team) to dominate through that disruption?
Does your team, unit and/or other company leadership understand the implications of the coming disruption and are they motivated to challenge the status quo as a result?
Develop your strategy – don’t push too far too fast
Now that you’ve established situational awareness, it’s time to get to work. This is where you put together your strategy to navigate around the defenders of the status quo (or convert them) and partner with the innovators. It’s critical to remember though that you can’t incentivize individuals or teams to act if they don’t possess both awareness of the benefits of the new technologies and methodologies AND are motivated to act even in the presence of the risk of change. Instead, the approach is to avoid allowing new technology adoptions being perceived as threatening to established individuals and teams or to convince those participants to join the initiative if they exhibit openness to being educated on the subject and are likely to experience an emotional reaction once they realize the truth. A couple of years ago, I had a conversation with a senior VP (now retired) at UPS that claimed Amazon was not a disruptive threat, even given the fact Amazon represented more than 10% of UPS package deliveries and was competing directly with UPS with little blue vans scouring suburban neighborhoods. And then there’s the fact of Amazon’s history of using their vendor partners/customers own data to compete with them directly. In such cases, it’s important to recognize that such an obviously wrong opinion is rooted in emotion and is very difficult to change. It’s better to work around these leaders than spend a lot of time trying to change their opinion, until you can point to specific business outcomes you can give them credit for. Also, if an organization has too many of these folks, it’s probably better to think about moving on – that ecosystem is too far from an inflection point to be able to embrace change. It may also be the right choice for that organization at that point to NOT change until a precipitating event occurs, meaning you either embrace the status quo yourself or move on.
To build momentum, it’s also important to use a Lean/Agile approach for delivering business value. Few leaders at this point are willing to wait years for a waterfall project to yield fruit.
Partner with fellow disruptors
Even if you’re a CEO, you can’t build an organizational culture of innovation that rewards adaptability over stability by simply hiring. You have other executives whose replacement would be too disruptive to current operations, and then of course, there’s the board. Consequently, it’s critical to identify and partner with individuals in the current ecosystem who are open to challenging the status quo because they feel (or can be made to feel) fear/greed/excitement about the existential threat and opportunity of using Generative AI with Enterprise Data. It’s also critical to make identifying these attributes part of the hiring process as well.

Walt Carter, in his book “We Can't Stay Here: Becoming A Great Change Captain” discusses the need to bring “misfit toys” (from the 1964 TV special “Rudolph the Red Nosed Reindeer”) into your organization to support change initiatives. By this, he is referring to individuals that exhibit adaptability, a preference for collaboration vs. competition, and a tendency to prioritize “us” vs. “me” - traits often penalized in organizations because most organizations prioritize stability over adaptability, yet critical for any ecosystem seeking to get in front of being disrupted.
Sell the car not the assembly line
The 1st Industrial revolution was one of the most disruptive, yet overall positive events in human history. And it all started with the rise of enabling systems and technologies like the rise of capitalism and the corporation, the rise of machines that made use of non biological forms of energy for manufacturing goods and mining, and the rise of nationalism to provide both funding and regulation. But one of the often overlooked drivers of the 1st revolution is the invention of the printing press in 1436. This invention unlocked an exponential advance in the ability of humans to communicate ideas broadly which made it possible for social ecosystems to reach inflection points in years rather than centuries.

The disruption of the Roman Catholic ecosystem via the Protestant Reformation is one such example. When Martin Luther nailed his “Ninety-five Theses or Disputation on the Power and Efficacy of Indulgences” on the door of the Wittenburg Castle Church in 1517, that was an inflection point in a social if there ever was one. And it was made possible because Luther was able to use the printing press to quickly and widely share his ideas in a way that made millions fearful that the Catholic Church had become too greedy and corrupt. This same type of mass communication in a more modern context is exactly why Generative AI has reached an inflection point, but Lean/Agile Data Fabrics have not. Martin Luther was able to reach outside of the clergy (a specialized group of experts unwilling to self-disrupt) to the broader population and create an emotional response in that much larger group to drive disruption in the specialist group.

Nearly 400 years later, Henry Ford achieved something similar when he disrupted the emerging automotive industry. While Ransom Olds received the 1st assembly line patent in 1901, the assembly line was nothing new. A similar process was being utilized by meat packers as early as 1870’s Chicago. In fact, it was a visit to a Swift and Company slaughterhouse by one of Ford’s employees, William "Pa" Klann, sometime around 1906 that is widely credited with introducing Ford to the concept. Once armed with the efficiencies of the assembly line, Ford was able to build awareness in a mass market, the emerging middle class and use that awareness to create FOMO for new middle class consumers wanting something that previously was only available as a luxury good because of cost. Unfortunately for most of Ford’s competition, their engineers were not adaptable enough to navigate the shift to mass production and their car companies ultimately failed.
“It is not the strongest of the species that survive, nor the most intelligent, but the one most responsive to change.”
It was the geometric growth in awareness and corresponding motivation to act in the larger ecosystem of middle class users that created the disruption inflection point in the smaller ecosystem of the automotive industry. The inflection point was therefore not the advent of assembly line in automotive manufacturing. The inflection point was awareness that middle class people could now afford a car grew exponentially to the point where the emergence of the new middle class market disrupted the automotive industry. To be successful innovating with Generative AI with data delivered by a Lean/Agile Data Fabric, you must do the same – Sell the business outcome, not the assembly line.
Your results must link directly to something your team, division, and company cares about; getting vertical alignment like this takes a lot of time and effort, but is a requirement for success. And the choice of business outcomes to tackle must also be ones that map most easily to each level in the hierarchy.
Run the Skunk works strategy for ecosystems that are behind

You’ve already done your homework and achieved situational awareness so you know the business outcomes possible by adopting AI. Now to navigate the landmines. While the ideal situation is one where there is a culture of innovation and everyone is motivated to collaborate and invest personally in transformation, that is an unlikely scenario. More likely, you will have some number of leaders in the organization who will try to block you because of their stake in the status quo, even if your company and/or industry is experiencing significant disruption. The best strategy here is to find and partner with one or more business champions who do want disruptive change and are willing to support your initiative from a budgetary perspective as well as work around the organizational obstacles. This will only work if your partners in data driven AI disruption have political cloud significantly greater than the naysayers and you’ve carefully selected projects that solve business cases for data driven AI that:
Avoid interference with existing systems protected by political interests in the organization (even if they work for you)
Initial install and 1st sprint completion are less than 3 months in duration
1st sprint creates a clear and significant business impact you don’t need to be technical to understand
Creates integration work that is easily repurposed for other items on the business’ AI and/or Data wish list
Know when to move on
In some cases, you’ll finish your investigation on where the people in your ecosystems are with respect to being disrupted by AI and Lean Data via Data Fabrics and realize you cannot foster the cultural changes needed to prepare for the coming disruption. A successful strategy for avoiding ecosystem disruption with data driven generative AI may not be possible because of the current state of culture in that ecosystem; you may have to decide to play the long game by waiting for the political landscape to shift and/or a company/industry inflection point, content yourself with working in an ecosystem on the wrong end of disruption (good for folks nearing retirement) or start the process of moving on now. Forcing the issue by fighting unwinnable political battles is not a good strategy. You’ll likely lose and suffer a loss in reputation as you’re pushed out anyways.

Steve Sasson, inventor of the Digital camera in 1975
This is actually a common situation. While Steve Sasson invented the digital camera in 1975, the leadership of his employer, Kodak, refused to market a digital camera until it was too late. Sasson continued working on digital cameras for Kodak until his retirement in 2009, but although Kodak made royalties for the patent, the leadership’s unwillingness to self cannibalize their traditional photography business ultimately led them to bankruptcy. Did Steve Sasson make a mistake staying at Kodak until the end? It depends on his priorities. Just like Steve Sasson, some of us will have to make some hard choices depending on our values, goals, priorities and where we are with respect to our careers.
Conclusion
It’s important to recognize that unless you are on the cusp of retirement, #AI is going to disrupt your life and you will experience much greater success if you are the disruptor (not the disruptee). It all comes down to the culture of the social and business ecosystems you are a part of and when those ecosystems reach inflection point were exponential growth in awareness turns to change in behavior en masse.
The pace of adoption of Generative AI and Lean Data at an exponential scale requires innovators to recognize and take advantage of disruptive inflection points. This necessitates fostering a culture of innovation and aligning with individuals open to change. Understanding the role of fear and greed in driving transformation is crucial, as seen in the adoption of AI. Recognizing the need for agile methodologies in data integration underscores the importance of putting the principals of Lean Data to work building a Data Fabric that can source the clean data needed at exponential scale to take advantage of Generative AI with Enterprise Data.
Please share!
Tyler Johnson
Cofounder, CTO PrivOps
Using Generative AI with Clean Data to Survive in Shark Infested Waters: Lean Data (Part 3)
In part 3 of this blog post series, we discuss how a data fabric can be used to implement techniques borrowed from lean manufacturing to optimize the time required to integrate training data for LLMs and maximize business results.
Introduction
With all the hype around generative AI, it’s not surprising many organizations are incorporating AI into their strategic plans. The problem is, without clean training data, large language models (LLMs) are worthless.

As organizations increasingly recognize the power of Artificial Intelligence (AI) in unlocking the value of data, the process of providing high-quality training data for LLMs is critical. In part 3 of this blog post series, we discuss how a data fabric can be used to implement techniques borrowed from lean manufacturing to optimize the time required to integrate training data for LLMs and maximize business results.
In many ways, the current state of data integration resembles pre-industrial manufacturing. Instead of an assembly line approach, individual “data craftsmen”, also known as (data engineers) in small teams, or in many cases single IT “heros”, build bespoke data architectures that don’t scale. This is very similar to the state of software application development before the advent of DevOps.

Now that organizations are open to the idea that AI is a key component of future competitiveness, they’ll soon realize that raw data is the input that AI converts into business outcomes; this fact that will drive organizations to borrow concepts from lean manufacturing, essentially creating data factories of their own. “Lean Data” is closely related to “Industry 4.0” but whereas Industry 4.0 describes all cyber-physical systems, Lean Data concerns itself with the optimization of data manufacturing (data pipeline) as part of a data factory (many data pipelines).
10 Key Concepts of Lean Data

Value
A core principle of Lean Data is to align data integration efforts with customer needs, cost optimization, and other AI driven efforts to improve an organization’s competitiveness. This is similar to Lean Manufacturing but extends beyond product value to all elements of an organization’s competitive strategy. A data fabric provides a unified and holistic view of the data ecosystem, enabling organizations to focus on minimizing time to business value. Unlike a data lake or data lakehouse, a data fabric creates the agility needed to “start with the end in mind”, that is to design their AI strategy to focus on business outcomes and work backward to design the AI/Data system taking advantage of the ability to change data pipelines on the fly as the business changes. Utilizing agile methodologies is a key component of value in Lean Data, and will be the topic of a future blog post in this series.
Value Streams

An effective data fabric approach facilitates the mapping of data flow in the integration process by providing a comprehensive view of data movement across the organization. By understanding how data flows through the fabric, organizations can optimize the integration pipeline, ensuring that the right data reaches the model training stages efficiently.
Flow

When implementing Lean Data, data fabrics must ensure a smooth, efficient, and continuous data flow by integrating data from various sources in real-time, batch or in between, depending on the requirements for each business outcome. In 1984, Eliyahu Goldratt introduced the concept of the “Theory of Constraints” in his seminal book, “The Goal”. Connectivity is a critical limiting factor in delivering clean training data to LLMs and other data monetization efforts. To minimize these constraints, a data fabric must connect to the broadest set of connection methods for both legacy and modern information systems. This includes not just modern interfaces like APIs and cloud storage, but SQL databases, flat files, SFTP sites, and other legacy data communication methods. A best practice is to leverage open source Javascript for connectivity because the broad array of JS connectors and software development kits (SDKs) supported by IT vendors, creating a force multiplier for ensuring all components are kept up to date via 3rd party vendor vulnerability detection and patching of their JS connectors. We are talking integration here, not data analytics where there are other purpose built options in Python, R and other programming languages.
The situation is not static; as business objectives (value) evolve, bottlenecks including physical constraints, business constraints, process constraints, and most importantly, people constraints will emerge. This requires a data fabric approach that facilitates identifying and addressing bottlenecks as they occur with a policy driven approach, like software defined and infrastructure as code (IaC) approaches seen in DevOps.
Pull
Lean Data enables a pull-based approach to data integration, where data is integrated on-demand as required by the outcome. Instead of pushing all available data, the data fabric must have the capability to dynamically pull training data from relevant sources, with the option for on-demand (event driven) or according to a schedule, depending on use case. The data fabric must also be able to implement automation that enables LLMs and other data requestors to request specific data subsets, thus reducing unnecessary data processing and storage costs.
Perfection
Lean Data promotes continuous data quality improvement by incorporating data governance and validation mechanisms. This ensures that data is accurate, reliable, and compliant with quality standards before being integrated into training datasets, leading to higher model performance. While many consider the evolution of data privacy regulations a source of data friction, it isn’t because of trust. A data fabric that incorporates standardized capabilities for consent management, data privacy masking, data lineage, validation, logging and error reporting actually increases trust and facilities both broader sharing of data and continuous improvement via agile processes.
Empowerment
Lean Data Empowerment is all about being able to trust your employees and stakeholders with significant tasks, including access to enterprise data through LLMs. LLMs that incorporate both foundational LLM training datasets and enterprise data are subject to data leakage that can put businesses at risk. Although vendors like Microsoft have announced LLM offerings that offer commercial protection from enterprise data leakage (like Bing Chat Enterprise), it’s not enough to protect against leakage outside the organization. Users, and by extension the LLM they use, need to be able to protect against data leakage between user roles as well. As an example, if an organization were to feed all sales data into an LLM, how would they prevent salespeople from poaching each other’s leads by accessing sales data through an LLM? A data fabric in place must provide the ability to govern the flow of and access to sensitive data either directly by users or by LLMs through automation.
Standardization

In Lean manufacturing, standardization refers to documenting steps and the sequences of those steps for creating standardized tasks. Lean Data refers to not just the documentation of steps (or components) and the sequencing of those steps in data pipelines, but the standardization of the data pipeline components themselves. By leveraging a data fabric with a minimal set of standard pipeline components, organizations can not just establish and enforce standardized data integration pipeline templates, but drastically reduce the complexity, time and cost required to build and maintain data pipelines, which results in reduced time to data, and reduced time to decision. An effective Data Fabric approach will utilize a minimum set of data pipeline components and a drag and drop user interface (UI) that makes sequencing steps simple. By defining consistent data pipeline components, an effective data fabric approach also ensures uniformity across all data pipelines, minimizing integration complexities.
Just in Time
In Lean Manufacturing, Just-in-time (JIT) refers to methods to reduce flow times in manufacturing systems and improve response times to customers and suppliers. While a data fabric can optimize data processing by enabling just-in-time data integration with policy defined data pipeline components, Lean Data JIT also refers to the just-in-time creation and change management of the data integration pipelines themselves as well as their outputs. The ability to apply agile methodologies to data integration is a requirement for meeting the value principle of Lean Data, consequently an effective data fabric approach seeks to drive the change management cost in building and maintaining data pipelines to zero where possible and to minimize it elsewhere.
Visual Management
A data fabric approach in support of Lean Data must offer real-time monitoring and visualization of data integration processes through intuitive user interfaces. Teams must be able to not only track data flow, processing times, and errors, but also provide reporting for the purposes of security and compliance. This empowers IT operations to make informed decisions and address issues promptly, cybersecurity professionals to perform security audits and build in security by design, and compliance professionals to ensure compliance with relevant data privacy and security regulations through data privacy by design.
Efficiency (Waste)
Waste in Lean Manufacturing refers to reducing or eliminating everything that does not add value (the 7 wastes), things like excess transportation costs, inventory, idle time, overprocessing, defects etc. to improve product quality, reduce production cost, and production time. In Lean Data, instead of the seven wastes, we have the 10 efficiencies. As with the wastes in Lean Manufacturing, Lean Data efficiency refers to addressing traditional form of waste, work and other costs that also don’t add value. In addition it also refers to opportunities to improve efficiency not traditionally thought of as sources of waste. In other words, Lean Data Efficiency seeks to eliminate waste while minimizing rework (or technical debt remediation) and maximizing reuse. Data fabrics can play a key role in optimizing the 10 Efficiencies of Lean Data:
The 10 Efficiencies of Lean Data

Change Management. Data fabrics minimize the cost of change management by making all parts of data pipelines configurable and able to be automated via policies. Data users can request schema changes via change requests that are fulfilled in minutes instead of days. A data fabric’s modular, standardized components also make it possible to quickly connect to new data sources and reuse existing work to create new data pipelines by copying existing pipelines or parts of pipelines.
Minimize rework. To minimize rework, a data fabric approach must be able to:
Connect to legacy systems easily to bypass technical debt (until other business value exists that justifies refactoring that technical debt)
Use modular data pipeline components to minimize the amount of work required to rework existing data pipelines. This maximizes the ability of operators to implement changes by only needing to modify small parts of data pipelines instead of starting from scratch. For example, if an HR department wanted to change HR systems, the data fabric only requires a change in the connector and mapper – all other downstream data pipeline components remain unchanged.
Eliminate dependencies between IT systems. Data fabrics isolate changes between existing IT systems by not requiring data changes in existing systems of record. Instead, the data fabric can easily transform input data into digestible output data via a low-code pipeline management interface and automation.
Minimize data pipeline sprawl. An effective data fabric approach requires data fabrics that have a hierarchical catalog system for managing both data pipelines and pipeline components.
Maximize Reuse. with a modular, composable architecture for building data pipelines, data fabrics maximize reuse by making it possible for operators to copy and modify existing data pipelines
Talent. Data fabrics help organizations maximize the productivity of its most skilled engineers and developers by eliminating 95% (or more) of custom development for building data pipelines with a low-code, drag and drop interface for building and managing data pipelines. As a result, organizations are able to utilize non-coding operational personnel for most data pipeline tasks. Expensive data architects and ETL developers are then able to span across more data pipelines by a factor of 100x.
Access Automation (Zero Trust). Given the sensitivity of data and need to govern that data with access and identity information for both human and non-human data requestors like LLMs, manual access management processes are too inefficient to scale to the 100’s to 10,000’s of data pipelines required. Since an effective data fabric approach requires that sensitive data be governed, data fabrics with automated access management capabilities are a requirement. By integrating employee and vendor systems with identity platforms (Azure AD, Okta, etc.), requestor identity is automatically established and data pipelines now can govern data effectively because they have accurate access and identity data at all times.
Security and Privacy Automation. In software development, DevSecOps is a term coined to refer to the idea that security is built into the application by design and from the beginning. DevOps engineers refer to this as “shift left”, referring to moving security implantations and reviews to the left of a project management Gantt chart. Lean Data seeks to improve efficiency in implementing and managing cyber security and data privacy governance in data integrations by “shifting left” privacy and cybersecurity requirements when building data pipelines. This concept in Lean Data is referred to as “Privacy and Security by design”. An efficient data fabric approach requires that the data fabric include standardized modular components that automate filtering in data pipelines based on consent and requestor identity.
Data Quality. How many times have we heard CDOs and data users complain about data quality? The problem is that traditional approaches to data integration lack efficient data validation capabilities. Lean Data seeks to optimize the processes required to clean data. Data fabrics help to optimize data cleansing by:
Quickly building connections to data validation software services that clean data.
Including the capability to inject custom data checks into data pipelines.
Interoperability. To create efficiency, Data fabrics maximize interoperability by making it possible to integrate with the widest set of legacy and modern systems possible (connectors) and streamline the transformation of input data models to output data models.
Transfer. Data Fabrics minimize data transfer costs by being able to easily configure subsets of data (input schemas) and make those subsets policy defined so operators can change pipeline input schemas on the fly and LLMs and other applications can automate input schema selection.
Storage. Data Fabrics minimize storage costs by eliminating the need for a data lake, warehouse, or lake house in most cases by providing just-in-time access to data from the primary systems of record. Data fabrics can also be used to create new systems of record with persistent storage, but this is not an aggregated lake, lakehouse or warehouse. The only other intermediate data storage is when performance or cost constraints require data to be persisted as part of a data pipeline.
Conclusion
Embracing Lean Data principles with the support of a data fabric is critical for organizations seeking to unlock the true potential of AI and derive maximum value from their data assets. By aligning data integration efforts with customer needs, optimizing data flow, and ensuring continuous data quality improvement, organizations can create efficient data manufacturing processes. Lean Data's pull-based approach and standardization of pipeline components reduce complexity and time required for data integration. Agile methodologies facilitate adapting to changing business objectives and addressing bottlenecks in real-time. Through Lean Data, organizations can eliminate waste, maximize reuse, and optimize various aspects of data integration, empowering them to stay at the forefront of innovation and competitiveness in the industry.
Please share if you like this content!
Tyler Johnson
Cofounder, CTO PrivOps